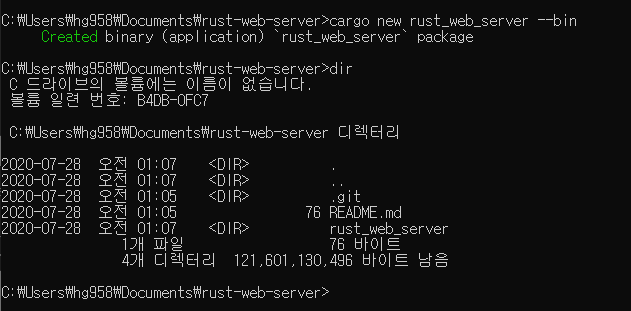
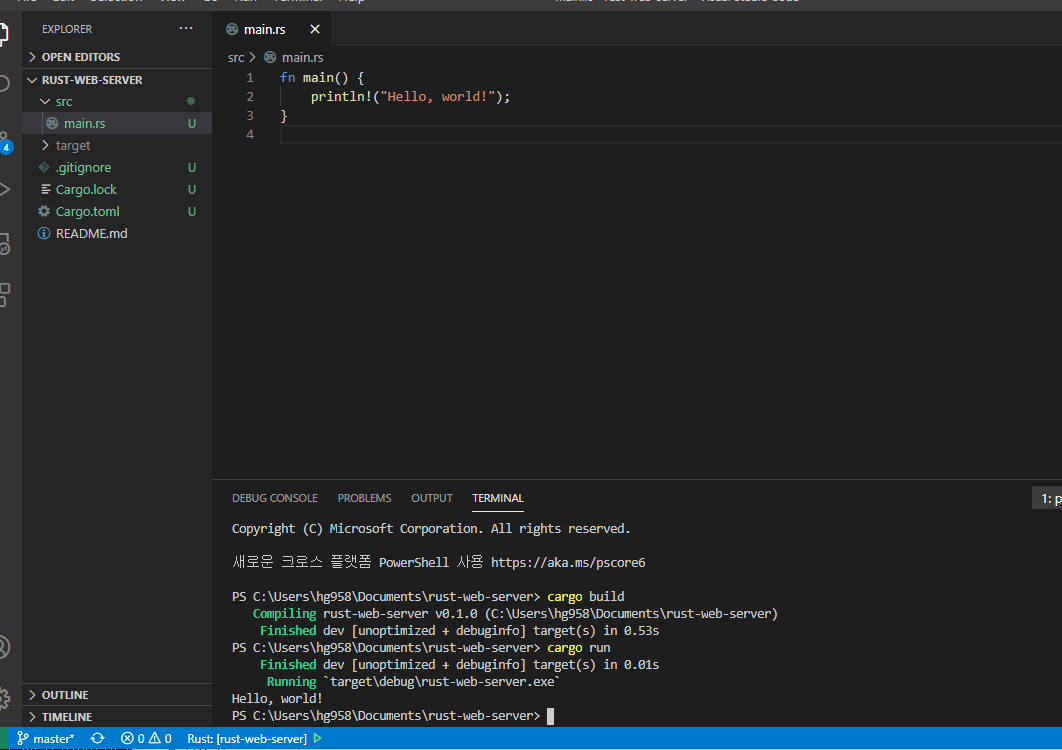
직전 포스팅에서 엑셀과 데이터베이스를 간단하게 비교를 해 봤는데, 이번 글은 직전 포스팅의 후속글입니다. 따라서 예상 독자도 이전글과 동일하게 엑셀로 현업 실무를 하는, 개발자가 아닌 사람입니다.
이번 포스팅에서는 DBMS의 몇가지 종류와 특징들, 그리고 SQL이 무엇인지와 스키마에 대해 간략하게 알아보고자 합니다.
데이터베이스 프로그램(DBMS: Database Management System)의 종류
데이터베이스를 다룰 수 있는 컴퓨터 프로그램들이 어떤 것이 있는지를 구체적으로 알아봅시다. 사실 데이터베이스 프로그램 뿐만 아니라 데이터베이스의 패러다임도 다양한 종류가 있습니다. 일단은 가장 전통적이면서도 강력한 관계형 데이터베이스(Relational Database, RDB) 프로그램에 대해 알아보도록 하겠습니다.
햄버거에 맥도날드, 롯데리아, KFC가 있듯이 DBMS에는 sqlite3, mysql, mariadb, postgre-sql, oracle db 시리즈, mongodb, cassandra 등등 여러가지가 있습니다.
사실 근래들어서 새로운 database의 한 패러다임인 nosql db라는 것도 있는데 해당 내용은 나중에 시간이 남게 되면 추가적으로 다루며, 이번에는 다루지 않겠습니다.
일단 데이터베이스를 다루는 프로그램을 두개의 범주로 나누어 보겠습니다.
파일형 Database(Flat-file database)
엑셀의 경우 그 데이터 값들은 하나의 파일에 다 들어가 있습니다. 마찬가지로 데이터베이스 중에서 하나의 파일 형태로 존재하는 데이터베이스가 있습니다. 대표적인 예시로 SQLite3가 있습니다. 그 외에도 마이크로소프트 액세스 같은 것들도 파일형 데이터베이스를 지원합니다. 이어서 나오는 서버형 데이터베이스에 비해서는 처리할수 있는 규모나 성능은 다소 떨어질 수 있으나, 파일 하나에 데이터가 다 들어간다는 간편성이 있습니다.
서버형 데이터베이스
개발자들이 자주 사용하는 형식의 데이터베이스인 서버형 데이터베이스입니다. 실제 IT 서비스에서 자주 사용되는 데이터베이스들이며 파일형 데이터베이스에 비해 큰 규모의 데이터들도 쉽게 처리하며, 하나의 파일 형태로 존재하는 것이 아닌 하나의 컴퓨터에서 지속적으로 실행되고 있는 형태의 프로그램으로 존재합니다. 따라서 그 컴퓨터와 네트워크 연결이 가능한 다른 컴퓨터에서 원격으로 데이터들을 조회하거나 다룰 수 있으며 따라서 여러명의 사용자가 동시에 사용하는 것도 가능합니다. 이에 따라 인증 및 권한과 동시성과 관련된 다양한 복잡한 기능들도 제공을 합니다. 이에 해당하는 DBMS에는 Mysql, MariaDB, PostgreSQL, 오라클 데이터베이스 등이 있습니다.
SQL(Structured Query Language)
직역하면 구조화된 질의어에 해당합니다. SQL은 선언형 프로그래밍 언어에 해당하며, 관계형 데이터베이스 관리 시스템(RDBMS)을 사용하기 위한 컴퓨터용 언어입니다. 엑셀의 경우 GUI(Graphical User Interface)를 지원하기 때문에, 눈에 보이는 버튼들을 누르고 셀을 클릭한 뒤 값을 입력하거나 하는 식으로 직관적인 방법으로 데이터들을 처리할 수 있지만, 앞서 위에서 언급한 (관계형) 데이터베이스들은 데이터를 처리하기 위해서 SQL이라고 하는 프로그래밍 언어를 작성한 뒤 이를 이용해서 명령을 내려야 합니다.
데이터를 조회할때는 Select 구문, 수정할때는 Update 구문, 생성할때는 Insert into 구문, 제거할때는 delete from 구문이라는 프로그래밍 언어 문법(Syntax)에 맞는 SQL 구문을 작성한 뒤, 이를 DBMS에 전송해서 작업들을 수행할 수 있습니다.
따라서 이 RDBMS 종류를 다루기 위해서는 SQL이라는 언어를 잘 알아야 하는 것이지요. 혹은 이 SQL 구문들을 자동으로 생성해서 동작하게 끔 하는 프로그램을 별도로 개발한다면, 엑셀을 다루듯이 클릭 등의 직관적인 방법으로 데이터를 다룰 수 있게 할 수 있습니다.
관계형 데이터베이스와 스키마
관계형 데이터베이스(Relational-Database)
앞에서 관계형 데이터베이스에 대해서 자세한 설명을 하지 않고 넘어왔지만, 여기서 간략하게 관계형 데이터베이스가 무엇인지 짚고 가겠습니다.
데이터베이스를 어떤 식으로 저장할지는 여러 패러다임들이 있었지만 지금 가장 많이 쓰이는 형식이 관계형 데이터베이스(Relational Database)이며, 데이터베이스를 표 형태로 표현한다라는 뜻이라고 보시면 됩니다.
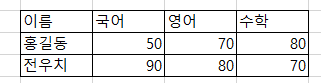
위 표를 보시면, 간단한 용어를 확인할 수 있는데, Relation(관계)는 표 자체를 뜻하고, Attribute는 특성값이라고 보시면 됩니다. 사실 엑셀도 표 형식이니 이해하기 어렵지 않을 것입니다.
엑셀에 위와 같은 데이터가 있다고 하면, 첫번째 행에 있는 이름, 국어, 영어, 수학 들은 attribute에 해당하며, 각각의 2번째 3번째 행은 tuple에 해당하게 됩니다. 이것이 표 형태로 있는 것이 relation이 됩니다.
이런 용어들은 크게 신경쓸 필요 없고, 다만 관계형 데이터베이스는 데이터를 위와 같은 표 형태로 나타낸다 라는 것만 기억하시면 됩니다.
데이터베이스 스키마
앞에서 관계형 데이터베이스가 표 형식을 따른다고 했습니다. 이때 이 "표의 형태가 데이터베이스 스키마"입니다.
위에 예시에서 들은 2명의 학생의 국어,영어,수학 성적에 대한 Relation의 스키마를 표현하자면 다음과 같겠습니다.
이름이라는 attribute는 text 데이터를 저장하고, 국어와 영어 수학이라는 attribute는 정수 값을 저장하는 형태를 띱니다.
이 내용 자체가 성적과 관련된 저 Relation의 스키마입니다.
그리고 이 Relation은 RDBMS 및 SQL에서는 테이블이라고 부릅니다. 테이블은 직역하면 표라는 뜻을 갖지요.
일단 용어에 대해 살짝 명확하게 하고 가자면, 스프레드시트와 엑셀은 의미에 있어서 차이가 있습니다. 스프레드시트는 표 형식으로 데이터를 처리할 수 있는 컴퓨터 프로그램을 뜻합니다. 엑셀은 마이크로소프트라는 회사에서 만든 스프레드 시트 프로그램의 상표명이라고 볼 수 있죠. 마치 스프레드 시트와 엑셀의 관계는 유리테이프와 스카치테이프, 고체풀과 딱풀, 라면과 삼양라면, 햄버거와 불고기버거의 관계라고 볼 수 있습니다. 엑셀외에도 한컴오피스에서 만든 한셀이라는 프로그램도 스프레드시트 프로그램 중 하나입니다. 엑셀이 제일 유명한 스프레드 시트 프로그램이니, 앞으로는 편의상 엑셀이라고 칭하겠습니다.
엑셀을 왜 쓸까요?
엑셀은 표 형식으로 데이터를 처리하는 스프레드시트 프로그램입니다. 따라서 표 형식으로 나타내면 편리한 데이터들을 처리하기 위해서 씁니다.
CRUD 데이터 처리
여기서 데이터 처리라는 것은 데이터 쓰기, 읽기, 바꾸기, 지우기와 같은 동작들인데, 이 용어들을 영어로 표현하면 Create, Read, Update, Delete인데 이 단어들의 앞글자를 따면 CRUD가 됩니다. 이 CRUD는 컴퓨터 프로그램에서 데이터를 처리할때 가장 기본이 되는 4가지 동작들입니다. 엑셀은 이 4가지 동작이 다 손쉽게 가능합니다.
Create를 할 때에는 엑셀의 빈 셀에 값을 쓰면 되고, Read는 해당 셀을 클릭해서 데이터를 확인해볼 수 있습니다. 검색이 필요한 경우 Ctrl + F를 눌러서 검색이 가능합니다. Update(수정)가 필요할때는 셀을 클릭해서 새로운 값을 입력하거나, F2를 누른 뒤 값을 변경하면 됩니다. Delete(삭제)는 해당 셀을 클릭한 뒤 키보드 delete 키를 누르면 됩니다.
다소 복잡한 데이터 처리
데이터 정렬이 필요할때에는, 칼럼 이름에 필터를 건 뒤, 오름차순 혹은 내림차순으로 정렬하기를 누르면 쉽게 정렬이 됩니다. 그 외에도 평균값을 구하거나, 총합을 구하거나, 순위를 구하거나 등의 다소 복잡한 데이터 연산이 필요한 경우 엑셀에 내장된 함수들을 이용해서 계산을 할 수 있습니다.
데이터베이스는 뭘까요?
사전적인 의미로는 여러사람들이 공유하여 사용할 목적으로 체계화하여 통합 및 관리하는 데이터 집합이라고 합니다. 데이터를 쉽게 잘 다룰 수 있도록 잘 해놓은 데이터 덩어리라고 보면 된다. 사실 기본적인 내용들은 엑셀과 다를 바 없는 것이, 똑같이 데이터를 다루고, CRUD 연산도 당연히 잘 됩니다.
Database vs DBMS(Database management system)
여기서 데이터베이스(Database)와 DBMS(Database Management System)의 차이를 살짝 짚고 넘어갑시다. 데이터베이스는 데이터들 모여있는 것, 데이터 그 자체를 의미하고, DBMS는 데이터 베이스를 처리하는 컴퓨터 프로그램입니다.
눈치채었을 수 있겠지만, 이제 언급할 것들은 사실 데이터베이스가 아닌 DBMS의 특징들이라고 볼 수 있습니다. 그냥 데이터베이스는 추상적인 개념들이고, DBMS는 우리가 당장 실무에서 써먹을 수 있는 녀석들이니 말입니다.
엑셀 vs 데이터베이스(DBMS)?
엑셀과 데이터베이스의 장단점을 매우 간단하게 비교하면 이렇습니다. 엑셀이 배우기는 훨씬 쉽고 직관적입니다. 데이터베이스는 익히고 사용하는데 지식이 더 많이 필요하고 어렵습니다.
대신 데이터베이스는 엑셀보다 더 좋은 성능과 기능들을 가지고 있습니다. 여기서 더 좋은 성능이라 함은, 엑셀의 경우 데이터가 몇 만개 정도만 되어도 컴퓨터가 버벅이고 느려지고 처리가 힘들어질 수 있으며, 데이터 개수의 제한이 명확하지만 데이터베이스의 경우는 그 보다 더 많은 개수의 데이터도 쉽고 빠르게 처리할 수 있습니다. 또한 엑셀에서 처리하는 것 보다 더 복잡할 수 있는 연산들을 처리할 수 있습니다.
그리고 엑셀의 경우 남과 데이터를 공유하려면, 엑셀파일을 저장한 뒤, 이 파일을 이메일 등을 통해서 공유를 해야 하는데, 데이터베이스의 경우 실시간으로 데이터 편집한 부분을 반영시켜서 남과 동시에 작업이 가능합니다.
구분
엑셀(스프레드시트)
데이터베이스(DBMS)
장점
직관적, 익히기 쉽다
사용 시 쿼리 언어에 능숙해야함 데이터 모델링 시 지식과 숙련도 필요
단점
많은 데이터 처리시 느려짐(저성능) 다소 복잡한 내용 처리 어려움 동시작업 불가능
많은 데이터 쉽게 처리(고성능) 복잡한 처리 가능 동시작업 가능
뭐 쉽게 생각하면, 데이터베이스가 익히기는 어렵지만 엑셀에서 할 수 있는 것들 대부분을 다 할 수 있고 성능도 더 좋고 강력합니다. 하지만 데이터 베이스를 잘 쓰기 위해서는 데이터베이스용 쿼리 언어인 SQL을 사용할 줄 알아야 하고, 데이터 모델링에 대한 지식과 숙련도도 필요합니다.
실제 소프트웨어 회사에서 데이터베이스의 성능을 극대화까지 끌어내기 위해서, 이러한 SQL 쿼리 작성과 데이터 모델링만 전문적으로 행하는 DBA라는 직무가 따로 있을 정도로 깊게 들어가면 매우 어려운 영역입니다.
하지만 그렇게까지 복잡하지 않은 데이터들을 처리할때에는 가볍게 공부해서 시도해볼 수 도 있을 것 같습니다.
언더바는 무시하는 값으로도 쓰일 수 있습니다. 해당 값을 unpack하기 싫다면, 그냥 _에다가 할당하면 됩니다.
## 값을 버립니다.
a, _, b = (1, 2, 3) # a = 1, b = 3, _에 2가 할당됩니다.
print(a, b)
## 여러개 값 버리기
## *(변수) 는 unpack할때, 여러개의 값을 하나의 변수에 저장할때 쓰입니다.
## 이는 확장된 Unpacking이라고 불리며,Python 3.x 버전에서만 가능합니다.
a, *_, b = (7, 6, 5, 4, 3, 2, 1)
print(a, b)
테스트를 해보니, _에다가 할당하면 _도 일반 변수처럼 쓰이고, 1번처럼 Last expression을 저장하지 않게 됩니다. del _를 통해 해당 변수를 삭제하면 1번때처럼 Last expression을 저장하게 됩니다.
3. 루프에서 사용
for 루프를 돌 때 사용할 수 있습니다. 아래처럼 쓰는 것도 하나의 방법이 됩니다.
## _를 이용해서 루프를 돕니다.
for _ in range(5):
print(_)
## 리스트 순회를 _를 이용해서 합니다.
## _ 를 일반 변수처럼 사용할 수 있습니다.
languages = ["Python", "JS", "PHP", "Java"]
for _ in languages:
print(_)
_ = 5
while _ < 10:
print(_, end = ' ') # 'end'의 기본값은 '\n'인데 이걸 변경해줍니다.
_ += 1
실행결과는 예상한 것과 같게 아래처럼 나옵니다.
0
1
2
3
4
Python
JS
PHP
Java
5 6 7 8 9
4. 숫자값의 구분
숫자값이 길다면, 자릿수 구분을 위해 _를 중간중간에 넣어줄 수 있습니다.
이진수값이나 16진수, 8진수 값도 동일하게 적용할 수 있습니다.
## 여러 숫자 표현법
## 아래 값들이 정확한지 확인하기위해 int 함수를 써 볼수도 있습니다.
million = 1_000_000
binary = 0b_0010
octa = 0o_64
hexa = 0x_23_ab
print(million)
print(binary)
print(octa)
print(hexa)
실행 결과는 아래와 같습니다.
1000000
2
52
9131
5. 언더바를 포함한 변수명들
변수, 함수, 클래스 명 등에 언더바가 사용될 수 있습니다.
앞에 하나의 언더바 _variable
뒤에 하나의 언더바 variable_
앞에 둘의 언더바 __variable
앞과 뒤에 두개의 언더바 __variable__
5.1 앞의 하나의 언더바
앞에 하나의 언더바로 시작하는 이름은, 내부 사용용입니다(internal use only). 일단 예시부터 봅시다.
이제 my_functions.py를 가져오기 위해 import 구문을 써보자. 파이썬은 언더바 하나로 시작한 이름들은 import하지 않는다.
>>> from my_functions import *
>>> func()
'datacamp'
>>> _private_func()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name '_private_func' is not defined
위의 코드 결과를 보다시피, _로 시작한 _private_func는 찾지를 못한다.
위와 같은 에러를 방지하기 위해, from module import *가 아닌 모듈 자체를 import를 해보자.
상속을 한 뒤, 초기화를 하는 과정에서 Sample의 맴버변수들에 값을 다 대입하고 있다.
overridden
overridden
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-2-4bf6884fbd34> in <module>()
9 print(obj2.a)
10 print(obj2._b)
---> 11 print(obj2.__c)
AttributeError: 'SecondClass' object has no attribute '__c'
__c를 찾지 못해서 에러가 발생했다. name mangline때문에 obj2.__c가 아닌 obj2.__SecondClass__c로 바뀌었다. obj2._SecondClass__c를 한번 출력해보자.
print(obj2._SecondClass__c)
overridden
편의상 결과도 같이 썼다.
그러면 _Sample__c는 어떻게 되었는지 한번 보자.
print(obj1._Sample__c)
3
mangle 된 이름으로 잘 있다.
맴버함수(메소드)를 이용해서 mangle 된 두개의 언더바로 시작하는 변수를 접근할 수 있다. 예시를 보자.
class SimpleClass:
def __init__(self):
self.__datacamp = "Excellent"
def get_datacamp(self):
return self.__datacamp
obj = SimpleClass()
print(obj.get_datacamp()) ## "Excellent"를 출력한다. __datacamp에 해당하는 값이다.
print(obj.__datacamp) ## 여기서 에러가 발생한다. 변수 이름이 바뀐다.
메소드(getter, setter)안에서는 잘 접근을 한다. 하지만 외부에서 멤버 변수로 직접 접근하려고 하면 에러가 난다.
언더바 2개로 시작하는 명명법은 변수뿐만 아니라 메소드 이름에도 적용이 가능하다. 예시를 보자.
class SimpleClass:
def __datacamp(self):
return "datacamp"
def call_datacamp(self):
return self.__datacamp()
obj = SimpleClass()
print(obj.call_datacamp()) ## __datacamp()의 리턴값과 같다.
print(obj.__datacamp()) ## 여기선 에러가 난다.
__로 시작한 함수는 안에서만 호출이 되는 용도라고 보면 될 것 같다.
다른 객체지향 언어에서 private access modifier(접근 지정자)의 역할이라고 보면 될 것 같다.
다른 예시를 한번 보자.
_SimpleClass__name = "datacamp"
class SimpleClass:
def return_name(self):
return __name
obj = SimpleClass()
print(obj.return_name()) ## "datacamp"를 출력하게 된다.
위와 같은 코드도 정상적으로 동작을 한다.
좀 특이한 방식의 개념이다.
5.4 앞뒤로 2개의 언더바
파이썬에서 앞뒤로 2개의 언더바로 둘러쌓인 명명법을 본 적이 있을 것이다. 이녀석들은 매직 메소드(magic method) 혹은 dunder 메소드라고 불린다.
root로 돌린 virtualbox에서 똑같이 이미지 import를 다시 하고 실행을 시키려니, 이번엔 좀 다른 메시지가 나왔다.
Kernel driver not installed (rc=-1908) The VirtualBox Linux kernel driver is either not loaded or not set up correctly. Please try setting it up again by executing
'/sbin/vboxconfig'
as root.
If your system has EFI Securie Boot enabled you may also need to sign the kernel modules (vboxdrv, vboxnetflt, vboxnetadp, vboxpci) before you can load them. Please see your Linux system's documentation for more information.
where: sublibOsInit what: 3 VERR_VM_DRIVER_NOT_INSTALLED(-1908) - The support driver is not installed. On linux, open returned ENOENT.
뭐 커널드라이버가 설치가 안됬니 뭐니 하면서 vboxconfig를 실행하라는데 찾아보니 나한테는 없는 프로그램이었다.
대충 구글링 해보니 스택오버플로에 아래와 같은 명령어로 설치를 하란다.
$ sudo apt install --reinstall -y virtualbox-dkms
치니까 apt가 apt-get -f install을 치라고 하더라. 그래서 그냥 쳤다.
$ sudo apt-get -f install
이제 vboxconfig라는 바이너리가 위에서 말하는 경로에 생겼다. sbin에 있는 바이너리니 당연 sudo 넣어서 실행을 해야겠다 싶었다.
$ sudo vboxconfig
근데 뭐 좀 되는 것 같더니만 fail을 내뿜는다. dmesg로 확인을 해보란다.
그래서 dmesg로 확인해보니, modprobe에서 에러가 났으며 해당 드라이버 서명이 제대로 안됬다고 한다.
modprobe는 커널 드라이버 로드하는 명령어이다.
맨 위에서 말한것 처럼 무선랜카드 드라이버 빌드해서 적제할려고 MOK.der라는 키들을 새로 만들었는데, 아마 이 키로 서명된게 아니라서 그런 것 같다.
대충 컨텍스트를 보니 vboxconfig를 실행하면 내 리눅스 시스템에 맞는 vbox용 드라이버를 빌드해서 사이닝 한 뒤 load까지 해주는데 내가 이 커널에서 신뢰하는 키를 새로 만들어버려서 등록을 했으니 signing이 제대로 안되는 것이다.
그래서 vboxconfig 로그메시지를 대충 보니, vboxdrv.sh라는 파일에서 빌드하고 서명하고 그런 동작들을 하는 것 같더라.
이번에는 다른 포스팅과는 다르게 책에 대한 리뷰 겸 홍보를 하려고 합니다. 보통 이런 글은 잘 쓰지 않지만, 지인인 동빈님이 작성하신 첫 종이책이기도 하고, 제가 리뷰어로서 참여한 책이기도 하니 한번 소개해보려고 합니다.
무작정 이 책이 좋다, 아니다 어떻다라기 보다는 객관적인 시선으로 이 책의 특징과 장점을 설명하고, 어떠한 사람들이 이 책을 읽으면 좋을 지에 대해 한번 글을 써 보도록 하겠습니다.
제가 알고리즘을 처음 공부할 때에는...
제가 알고리즘 문제풀이를 본격적으로 시작했던 때가 딱 3년전인 2017년 즈음 이었던것 같습니다. 그때는 컴퓨터공학과 학부에서 내주는 과제수준의 Naive한 다중 for-loop으로 코드를 짜거나, 함수의 재귀 개념에 스택, 링크드리스트라는게 있다 정도만 아는 정도의 수준이었습니다.
그때 알고리즘 분야의 정석 교과서라고 불리던 종만북을 구입을 했었고, 앞에 수십페이지에 달하는 서문을 읽고, 첫번째 문제인 Festival을 알고스팟에서 풀어보려고 했었죠. 당시 종만북 책에는 해당 문제에 대한 해답이 없었던걸로 기억하고, 고로 Festival 문제를 제대로 풀지 못하고 바로 종만북은 책장에 박혀서 먼지가 쌓여갔던 기억이 있습니다.
당시의 저에는 매우 어려운 문제였던 것이지요.
그러다가 학교 선배의 추천으로 정보올림피아드 초등부 문제를 풀었었고, 풀다가 막히면 좌절감에 공부를 쉬기도 했었죠. 그리고 강남역에서 있었던 백준님의 오프라인 강의도 돈을 내고 들었었습니다. 제대로 공부해보겠답시고 학부 4학년에 학교 알고리즘 동아리의 문을 두드렸기도 했고, 그때 들은 코드포스에 참여하면서 혼자서 이것저것 시도해보고 막히면 잠시 쉬었다가 다시 공부하고 이런 과정들의 연속이었습니다.
어쨋든 시간이 지나고 경험이 쌓이면서 지금은 왠만한 국내 기업들의 코딩테스트에서는 떨어지지 않을 정도의 기반이 쌓이긴 했지만, 꽤나 시행착오도 많이 했었고 중간에 어려운 난이도에 부딪혀서 잠시 공부를 포기하며 쉬는 기간들도 꽤 많았습니다.
3년전의 과거의 저에게 지금 이 책이 주어진다면, 좀 더 효율적이고 덜 좌절하면서 공부를 할 수 있었지 않았을까 하는 생각이 듭니다.
그래서 이 책의 특/장점은 무엇이냐면
동빈님이 쓰신 이 책의 특징과 장점이라고 하면, 아마 다음과 같은 항목들이지 싶습니다.
취업용 코딩테스트의 최신 트랜드 반영
알고리즘 문제풀이를 공부하는 사람들은 이유가 다양하지만, 일반적으로는 취미용이나 대회용을 타겟으로 한 책들이 많습니다. 취업용 문제풀이의 경우는 취미용이나 대회용 만큼의 고급/심화 내용을 포함하진 않고, 취업용은 이 대회용 문제들의 부분집합이라고 볼 수 있습니다. 물론 고급 내용들도 공부를 하면 무조건 좋지만, 효율적으로 취직을 타겟으로 공부를 할 때에는 조금 돌아가는 부분이 있을 수 있습니다.
이 책에는 취업용 코딩테스트에서 나올 법 한 것들을 모두 잘 커버하며 잘 짜여진 커리큘럼이 있으며, 최근 기출문제들과 관련 유형들을 잘 커버하고 있습니다.
유명한 종만북과 비교를 하자면, 종만북은 책의 목적이 취업용 코딩테스트를 위한 책이 아니며 책이 쓰인지도 꽤 오래된 편입니다.
알고리즘 문제풀이를 처음 접하는 사람들을 위한 난이도
보통 취업용 코딩테스트를 준비하는 분들은 하나 정도의 프로그래밍 언어를 사용할 줄 알며, 취직 준비를 위해서 알고리즘 문제풀이를 처음 공부하는 사람들이 많습니다. 이미 프로그래밍 대회 등을 준비했던 사람들에게는 따로 준비가 필요없을 수 있거든요. 이렇게 알고리즘 문제풀이에 처음 입문하는 사람들도 쉽게 이해하며 단계별로 계단을 밟아가듯 핵심 개념들을 쉽게 이해할 수 있도록, 이러한 독자들의 눈높이에 맞도록 쓰여진 책이라고 생각합니다.
종만북과 비교를 하자면, 종만북은 예상독자와 책 읽는 목적 자체가 좀 더 향상된 실력에 맞추어져 있어서, 알고리즘 문제풀이를 처음 접하는 사람에게는 진입장벽이 다소 있어서 책을 읽는 처음부터 어느정도 좌절을 할 수 있습니다.
파이썬 및 C++/Java 풀이 제공
코딩테스트 시 3대장 언어가 C/C++, Java, Python입니다. 전통적인 알고리즘 책들은 보통 C++ 코드를 고수하는 경우가 많습니다. 저 역시 알고리즘 문제 풀이 입문을 위해서 PS스타일의 C++와 C++ STL을 따로 공부하며 시간을 투자했습니다. 하지만 요즘에는 컴퓨터 공학 전공자 뿐만 아니라, 그 외의 산업공학과나 수학과 통계학과 경영학과 등 다양한 전공자들이 코딩을 배우는 경우가 많으며, 보통 이 경우 첫 입문 언어로 파이썬을 많이들 배웁니다. 이러한 분들에게 파이썬으로 코딩테스트 문제 풀이를 도와주는 책으로써 가치가 있고, 파이썬 뿐 만 아니라 C++과 Java 풀이 코드도 github를 통해 제공을 하여 공부에 도움을 줍니다.
지속적인 학습을 위한 리소스 제공
저자인 동빈님은 원래 유투브를 통해서 무료 개발과 SW관련 강의들을 많이 찍던 컨텐츠 크리에이터로써, 책과 관련된 강의들도 유투브를 통해 제공을 하고, 정답 코드 들도 친절한 주석과 함께 github에 공개되어 있습니다. 컴퓨터교육과 전공자 출신 답게 전달력있는 강의를 잘 제공하며, 수 많은 교육 경험들이 어우러진 동빈님의 컨텐츠는 공부를 할 방향과 내용들을 쉽게쉽게 이해할 수 있게 해줍니다.
어떤 사람들이 읽으면 좋은가?
3년전의 저에게 추천해주고 싶은 책입니다. 여태까지 알고리즘 문제해결 분야에 발을 담그지 않았다가, 이제 곧 취직 준비를 해야 해서 코딩테스트를 준비를 해야 하는 경우, 이 책에 있는 공부법대로 그대로 실시하면 됩니다. 최신 트랜드도 그대로 반영하고 있기 때문에 지금으로서는 이보다 더 가성비 좋은 선택은 없지 않을까 하는 생각이 듭니다.
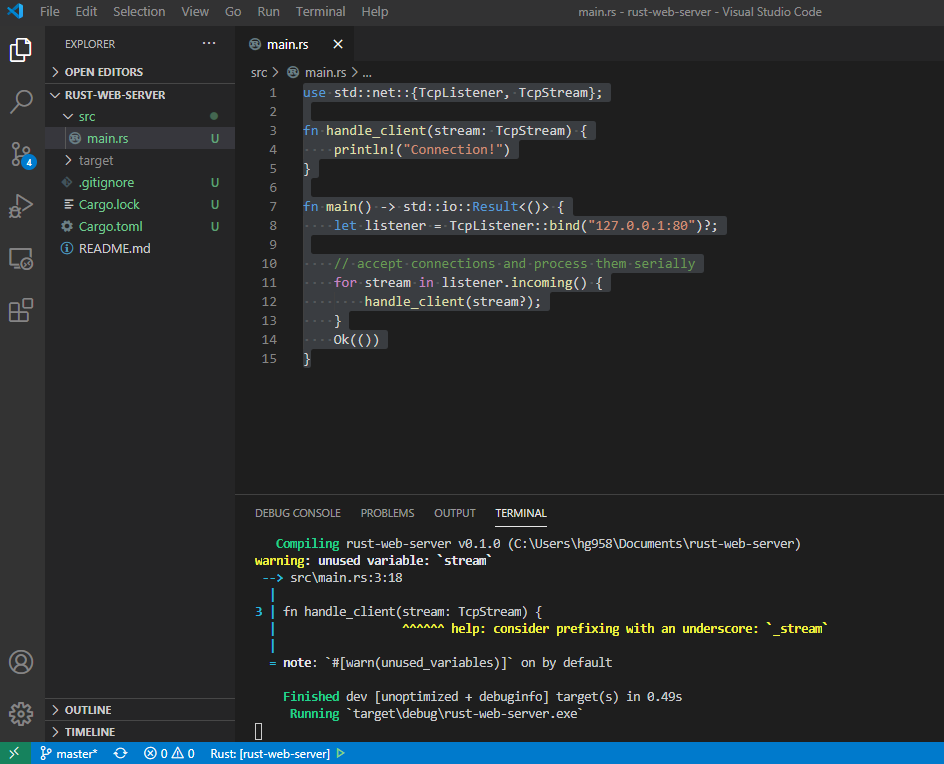
TcpListener라는 녀석이 있다. 일단 소캣을 하나 열어서 Listening하는 예제 코드가 있으니 한번 테스트 해보자.
use std::net::{TcpListener, TcpStream};
fn handle_client(stream: TcpStream) {
println!("Connection!")
}
fn main() -> std::io::Result<()> {
let listener = TcpListener::bind("127.0.0.1:80")?;
// accept connections and process them serially
for stream in listener.incoming() {
handle_client(stream?);
}
Ok(())
}
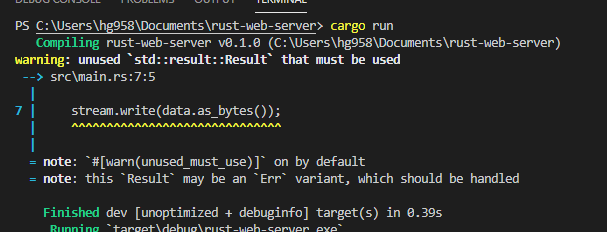
stream.write라고 하면 될 것 같은데, 사이에 &는 뭐고 ?는 또 뭔지 모르겠다.
찾아보니, &는 burrow라고 해서 인자를 넘겨줄 때, C++의 Reference variable 처럼 Call by reference로 넘기도록 하는 것이고, ?는 Result<T>를 리턴하는 값을 unwrap을 자동적으로 해주도록 하는 매크로이다.
웹 브라우저로 요청을 보내보니, Response는 안오긴 하는데 Connection이라고 찍히긴 한다.
그래서 대충 static한 HTTP Response를 찍도록 조금 변경해 보았다.
use std::net::{TcpListener, TcpStream};
use std::io::{Write};
fn handle_client(mut stream: TcpStream) {
println!("Connection!");
let data = "HTTP/1.1 200 OK\r\nContent-Type: text/html; charset=iso-8859-1\r\nConnection: close\r\nContent-Length: 14\r\n\r\nHello world!\r\n";
stream.write(data.as_bytes());
}
fn main() -> std::io::Result<()> {
let listener = TcpListener::bind("127.0.0.1:80")?;
// accept connections and process them serially
for stream in listener.incoming() {
handle_client(stream?);
}
Ok(())
}
그래서 브라우저로 접속을 해볼려고 했는데, 여러번 하면 한번정도 성공하는듯?? 왜 되었다 안되었다 하는지 모르겠다.
성공하는 확률은 10%정도로 뭔가 Tcp 연결을 잘 못 짠거같긴 하다.
그리고 빌드할때마다 다음 warning이 뜬다.
에러 핸들링을 제대로 안해서 그런 것 같다.
아래와 같이 코드를 바꾸니 warning은 안뜨긴 한다만, 여전히 응답은 제대로 안된다.
use std::net::{TcpListener, TcpStream};
use std::io::{Write};
fn handle_client(mut stream: TcpStream) {
println!("Connection!");
let data = "HTTP/1.1 200 OK\r\nContent-Type: text/html; charset=iso-8859-1\r\nConnection: close\r\nContent-Length: 14\r\n\r\nHello world!\r\n";
stream.write(data.as_bytes()).expect("Response error");
}
fn main() -> std::io::Result<()> {
let listener = TcpListener::bind("127.0.0.1:80")?;
// accept connections and process them serially
for stream in listener.incoming() {
handle_client(stream?);
}
Ok(())
}
근데 약간 이상한것은, Ubuntu 16.04에서 Firefox로 접속하니, hello world!가 잘 찍힌다.
왜 Windows 10에서 크롬으로 접속을 하면 제대로 안되는 것일까..?
나중에 확인해보니, tcpstream 마지막에 flush를 해 주니, chrome이든 firefox든 둘 다 잘 돌아간다.
대충 아래와 같은 코드로 고쳐보았다. /로 요청할때와 그 외의 경로로 요청할때의 응답이 다르다.
from_utf8_lossy는 u8 byte stream 값을 readable한 문자열로 변경해주는 함수이다. lossy는 유효하지 않은 UTF-8 배열을 만났을때 어떻게 처리할 것인가에 대한 내용이다. 유효하지 않은 배열 값은 U+FFFD Replacement character라는 값으로 바꾸게 된다.
use std::net::{TcpListener, TcpStream};
use std::io::{Write};
use std::io::prelude::*;
fn handle_client(mut stream: TcpStream) {
//get request and dump
let mut request = [0; 1024];
stream.read(&mut request).unwrap();
println!("Received HTTP Request...\n{}", String::from_utf8_lossy(&request[..]));
let response;
if request.starts_with(b"GET / HTTP/1.1\r\n") {
//send hello world response
response = "HTTP/1.1 200 OK\r\nContent-Type: text/html; charset=iso-8859-1\r\nConnection: close\r\nContent-Length: 14\r\n\r\nHello world!\r\n";
} else {
response = "HTTP/1.1 200 OK\r\nContent-Type: text/html; charset=iso-8859-1\r\nConnection: close\r\nContent-Length: 4\r\n\r\nNope\r\n";
}
stream.write(response.as_bytes()).unwrap();
stream.flush().unwrap();
}
fn main() -> std::io::Result<()> {
let server = "127.0.0.1:1024";
let listener = TcpListener::bind(server)?;
// accept connections and process them serially
println!("Server is running on {}...", server);
for stream in listener.incoming() {
handle_client(stream?);
}
Ok(())
}
인문학을 전공한 친구의 요청으로, 코딩을 전혀 접해보지 않은 사람을 대상으로 한 "코딩이란 무엇일까?"라는 주제로 포스팅을 해보게 되었다. 이해하기 쉬운 글을 쓰기 위해서, 필자가 쓴 글이 다소 엄밀한 정의와는 거리가 있을 수 있고 예시나 비유를 많이 들 수 있지만, 사전적인 정의보다는 전체적인 흐름을 이해하는데 초점을 맞추어서 글을 읽어주기를 바란다.
코딩이뭔데?
코딩은 영어로 coding인데, 부호를 나타내는 code라는 단어 뒤에 ing가 들어가게 된다. 사전적인 의미로 code는 부호라는 뜻이고, ing은 이 부호를 작성하는 것, 혹은 부호로 바꾸는 것 이라는 뜻이 된다.
여기서 코드(부호)라는 것은 컴퓨터가 처리할 수 있는 명령어라고 보면 된다. 크게 소스코드(source code)와 머신코드(machine code)로 나눌 수 있는데, 이 부분은 자세히는 다루지 않도록 하겠다.
그래서 코딩이란 컴퓨터에게 일을 시키기 위한 코드를 작성하는 것이라고 볼 수 있다.
그러면 프로그래밍은?
프로그래밍은 프로그램을 만드는 것을 프로그래밍이라고 한다. 프로그램은 코드의 모음집이다. 우리가 흔히 쓰는 윈도우 10같은 운영체제도 프로그램이고, 인터넷 익스플로러나 크롬 같은 웹 브라우저도 프로그램이다. 이런 프로그램을 작성하는 것이 프로그래밍이다.
코딩이랑 사실 큰 뜻의 차이는 없고, 코딩은 프로그래밍보다는 좀더 가볍게 적은 양의 코드를 작성한다는 뉘앙스의 차이가 있을 뿐이다.
그러면 코딩을 배우면 무엇을 할 수 있나?
코딩이 컴퓨터에 명령을 내리는 코드를 작성하는 것이니, 당연 코딩을 할 수 있으면 컴퓨터에 명령을 내릴 수 있다.
코딩을 몰라도 명령을 내릴 수 있는데?
맞다 우리는 이미 기본적인 컴퓨터를 사용할 줄 안다. 전원버튼을 눌러서 컴퓨터의 전원을 킬 수 있고, 웹 브라우저를 실행해서 웹 서핑을 할 수 있다. 이미 우리는 코딩을 할 줄 모르지만, 컴퓨터를 사용할 수 있다.
하지만 우리가 이렇게 컴퓨터를 사용하는 것은, 이미 잘 만들어진 다양하고 유용한 컴퓨터 프로그램들이 잘 존재하기 때문이다.
장부같은것을 관리하기 위해서는 엑셀과 같은 스프레드시트 프로그램을 이용하고, 발표자료를 만들기 위해서는 파워포인트같은 프레젠테이션 프로그램을 이용한다. 문서작업을 하기 위해서는 워드와 같은 워드프로세서 프로그램을 이용한다.
그래서 코딩이 왜 유용한건데?
윗 단락에서 컴퓨터로 할 수 있는 다양한 작업들의 예시를 보았다. 그런데 한번 상상해보자. 만약 내가 컴퓨터를 통해서 하려는 작업과 부합하는 프로그램이 없다면? 아니면 가능은 하지만 매우 비효율적으로 해야한다면?
비효율적인 반복 작업을 자동화
예를 하나 들어보자. 당신은 어떤 기업의 행정직으로 입사를 하게 되었다. 당신이 해야 할 일은 회사 전산 시스템에 접속해서 최근 5개년치 회계장부 파일을 모조리 프린트 해야 한다. 그런데 이 회계 장부 파일의 개수가 매우 많아서 하나하나 전산시스템에서 찾아내서 다운로드 받은 뒤, 인쇄를 하려니 단순반복 작업을 매우 많이 해야 한다.
이럴 때, 당신이 코딩을 할 수 있다면 이러한 반복작업들을 처리해주는 프로그램을 작성한 뒤, 이 프로그램이 일을 대신 하도록 맡기고, 당신은 커피한잔의 여유를 가지면서 쉴 수 있다.
실제로 이러한 사례들은 꽤 있으며, 그 중 하나 화제가 되었던 사건이 있다. 아래 유투브 링크를 클릭해서 사례를 참고해보도록 하자.
요즘에는 사람들이 쓸만한 기능에 대한 프로그램들이 꽤나 많이 공유되어 있는 편이다. 하지만 최신기술에 대한 프로그램이나, 특수한 상황에서만 쓰이는 프로그램 등은 누군가가 만들어놓은 경우가 없을 수 있는데 이러한 경우 프로그래밍 능력이 있는 사람에게 돈을 지불하고 외주를 주거나, 직접 해당 프로그램을 작성하거나 해야 한다. 이러한 경우에도 코딩 능력이 있다면 직접 프로그램을 작성할 수 있게 된다
기타 사례들
만약 본인이 유럽여행을 다녀오면서 수 많은 사진을 찍었는데, 이 사진들의 이름을 적절히 변경해서 관리하고 싶을 수 있다. 수천장의 사진의 이름을 일일히 변경할수도 있지만, 사진들을 찍은 시간 순서대로 정렬해서 일정 범위의 사진의 이름 앞에 찍은 도시이름을 포함해서 변경하고 싶을 수 있다. 예컨데 IMG_001 부터 IMG_100까지는 파리_001부터 파리_100 와 같은 식으로 말이다. 이런 경우 파이썬 이나 윈도우 배치 파일을 작성해서 파일명을 한꺼번에 바꾸거나, 다크네이머같은 프로그램을 이용해서 변경할 수 도 있다.
이와 같이 코딩능력이 있거나, 각기 필요한 상황에 쓸 수 있는 프로그램을 안다면 유용하게 사용하여 작업시간들을 단축할 수 있다
Security by obscurity 또는 Security through obscurity라고 부르는 이 녀석은, 어떤 시스템이나 컴포넌트의 보안성을 설계나 구현을 알려지지 않게 하는것에 의존하는 것을 뜻한다.
이 방식만을 이용해서 보안을 적용하는것은 추천되지 않고 있다.
내부 구조가 어떻게 생겨먹었는지 알 수 없게 하는 것으로 보안성을 만든다라는 것인데, 약간 말이 이상할 수 있으니 예를 들어보자.
예시
어떤 컴퓨터가 공공장소에 놓여져 있다. 어떤 사람이 그 컴퓨터를 무단으로 사용하려고(공격하려고)하는데, 버튼을 몇개 눌러보니 윈도우 컴퓨터임을 알 수 있고, 그 윈도우 버전에서 비밀번호 없이 로그인을 할 수 있는 방법이 있음을 알아서 그를 이용해서 로그인을 해서 안에 저장된 자료들을 무단으로 사용하고 온갖 것들을 할 수 있다.
그런데 만약 해당 컴퓨터에 Mac OS가 설치되어 있었고, 공격자는 Mac OS를 사용해본 적이 없었다. 그래서 공격을 할 수 없었다고 해보자.
공격자는 Mac OS에 대한 이해가 부족하기 때문에 공격에 실패했다. 이러한 방식의 보안을 Security by obscurity라고 볼 수 있다.
물론 여기서 아니 누가 Mac OS를 몰라?라고 생각할 수 있는데 그러면 AIX 운영체제나 더 오래된 옛날 Unix 운영체제, Dos 운영체제 등의 예시를 들어보자.
잘 안쓰이고 오래되어 잊혀진 구조를 갖는것으로 보안성을 획득하는 것이라고 보면된다.
다른 예시를 들어보면, 어떤 파일을 압축을 해서 저장을 한다고 해 보자. 널리 쓰이는 deflate 알고리즘이나 PK zip, gunzip 등의 압축 포맷으로 압축을 하면, 해당 포맷에 대한 압축해제를 하는 프로그램과 알고리즘들이 잘 공개되어 있어서 쉽게 압축을 풀 수 있다. 하지만 만약 공개되지 않은 새로운 압축 알고리즘, 자신들만 쓰는 압축 알고리즘으로 압축을 해 놓으면 이것이 암호화가 아니지만, 그 알고리즘을 모르기 때문에 압축을 풀 수 없다.
이 압축 알고리즘을 알려지지 않도록(비밀로 유지)해서 보안을 성취하는 것 역시 security by obscurity라고 볼 수 있다.
Embedded 장비에서 쓰는 파일시스템 중 일부 파일시스템의 Meta data format을 조금 바꾸어서, 일반적인 binwalk와 같은 firmware extractor로 정상적으로 추출되지 않도록 하는 방식도 security by obscurity라고 볼 수 있다.
Security by obscurity는 자물쇠공 알프래드 찰스 홉스라는 사람을 상대하기 위해 사용되었었다. 찰스 홉스는 1851년에 대중들에게 최첨단 자물쇠도 쉽게 따버릴 수 있다는것을 몸소 보여준 사람이다. "자물쇠 설계의 보안 결합을 노출하면 범죄자에게 더욱더 취약해질 수 있다"라는 우려에 대해서 그는, "도둑들은 해당 부분에 대해 매우 열심히며, 우리가 알고 있는 것 보다 이미 더 많은 것들을 알고 있다"라고 말했다.
Security through obscurity에 대한 공식적인 문헌은 매우 부족하다. 예를들어서 보안공학에 관한 책은 1883년 부터 kerckhoffs의 교리를 계속 인용하는데, 예를 들어서 핵 명령 통제를 비밀로 해야 할지 개방해야 할지에 대한 토론에서:
우발적인 전쟁의 가능성을 줄이는 것이 핵 명령 통제 기술을 비밀로 두는 것 보다 더 중요하다. 이는 Kerchkhoffs의 교리의 현대적인 재해석에 해당하며, 보안 시스템은 구조를 모호하게 두는 방식이 아닌 키에 의존해야 한다. 라고 말했다.
(의역을 해보자면, 핵 기술을 비밀로 두는 것 보다, 전쟁의 가능성이 더 중요하다는 것인데, 핵 기술을 공개를 하면 서로 핵을 갖기 때문에 서로 조심하게 되어 전쟁의 가능성이 줄어든다 그런 이야기를 하는 것 같아요)
법학분야에서 Peter Swire는 "모호함을 통한 보안은 환상", "느슨한 입술이 배를 가라 앉히는" 군사 개념과, 어떻게 경쟁이 인센티브를 공개하게 만드는지에 대한 상충관계에 대한 글을 썼다. (security by obscurity가 구현한 내용들을 비밀로 두는 것으로 보안을 성취하는 것인데, 공개 경쟁을 하기 위해서는 이러한 구현 내용들을 공개해야 한다는 것. 즉 security by obscurity에 반대하는 내용인 것 같습니다.)
비판
Security by obscurity만 가지고 보안성을 담보하는 것은 추천되지 않고, 표준정책에도 좋지 않습니다. 미국의 NIST에서는 이 방식의 보안에 대해 반대되는 의견을 내고 있으며 이는, "시스템 보안은 구현이나 컴포넌트의 비밀성에 의존하면 안됩니다."라는 문구로 대변됩니다.
이 방식의 보안은, security by design(설계에 의한 보안)과 open security(공개 보안)과 대조지만, 실제 프로젝트들은 이러한 전략들을 모두 사용하곤 합니다.