가끔 공부나 일 하기 싫을때 글을 한번씩 쓰려고 하는데, 이번에는 캐시 메모리에 대해 이야기 해보고자 한다. 사실 캐시와 관련된 배경 지식들이 짜잘한 것들이 꽤나 있는데 이것들을 한번에 다 다루려고 하면 글이 길어지고 작성하기도 귀찮아지니, 조금씩 점진적으로 글 내용을 추가해서 작성해보고자 한다.
일단 캐시 메모리와 관련된 내용은 컴퓨터공학과 학부 전공 과목 중 컴퓨터구조(Computer Architecture) 과목에서 자세히 다룬다. 하지만 컴퓨터공학을 전공하지 않았거나, 해당 과목을 수강하지 않았거나, 아니면 오래되어서 까먹었다던지 하는 사람들에게 다시 리마인드 시켜주거나 개괄적인 내용을 전달할 수 있는 글을 작성해보고자 한다.
캐시와 버퍼의 차이
캐시(Cache)와 많이 혼용되는 개념 중 버퍼(buffer)라는 것이 있는데, 이 둘은 일단 존재 목적이 다르다. 캐시는 처리속도가 차이나는 장치간의 상호작용 시, 이 처리속도 차이로 인한 성능 저하를 완화시켜 성능을 향상시켜주는 역할을 한다. 캐시와는 달리 버퍼는 데이터를 일시적으로 옮기면서 손실을 방지하는 보조 장치 같은 느낌이다.
이렇게만 설명하면 아직 감이 잘 안올 것인데, 간단한 예시를 들어보겠다. 부대찌게 식당에 가서 큰 부대찌게 그릇이 있고, 내 앞에는 앞접시가 있다. 보통 이 앞접시에 부대찌개를 일정량 덜어서 먹을 것인데, 부대찌게 그릇이 주 메모리(Main Memory)이고, 앞접시가 캐시 메모리(Cache Memory)라고 볼 수 있다.
이때 중요한 점은, 큰 부대찌게 그릇은 양이 크고, 앞접시는 양이 작다. 그리고 밥 먹는 사람이 부대찌개 그릇까지 수저를 가져가서 음식을 퍼나르는데는 시간이 많이 걸리고, 앞접시까지 수저를 가져가는 데에는 시간이 조금 걸린다. 부대찌게 그릇까지 닿는데에 100초가 걸리고, 앞접시 까지 닿는데에 1초가 걸린다면 이는 실제 주 메모리와 캐시 메모리와의 관계가 비슷해진다. (주 메모리와 캐시 메모리의 읽기쓰기의 속도 차이는 100배 정도라고 한다). 여기 까지 이해했으면 여러분은 캐시 메모리에 대해 어느정도 감을 잡았을 것이다.
그러면 버퍼에 대한 예시도 한번 들어보자.
여러분들은 C 언어 에서 swap 함수에 대해 한번들어본 적이 있을 것이다. swap 함수는 인자로 들어온 2개의 변수의 값을 서로 바꾸어 주는 역할을 한다.
void swap(int& a, int& b) {
int buffer = a;
a = b;
b = tmp;
}자 위에 코드에서 여러분은 이제 버퍼가 뭔지 알게 되었다. a변수와 b변수의 값을 서로 바꿀 때, 그냥 대입(assignment)를 하면 기존의 a변수에 있던 값을 잃어버리게 되므로, 이 값을 임시로 저장할 공간이 필요하다. 그래서 임시 지역 변수를 하나 선언하는데 이 변수의 이름이 buffer이고 실제로 버퍼이다. 보통 버퍼라 하면 배열 형태로 된 것들만 생각하지만, 용도만 생각해 보면 이러한 변수도 버퍼가 된다.
메모리 계층구조 구성요소들
자 이제 캐시가 왜 필요한지 구체적으로 알아보자.
컴퓨터는 다양한 장치들로 구성되어 있지만 가장 필수적인 두가지를 한번 고르자면 CPU와 주 메모리(Main memory)이다. CPU는 기계어 Instruction 들을 fetch 해서 실행하고, 이 기계어 내용들에 따른 적절한 연산을 수행한다. 이 연산들은 대부분 레지스터나 메모리에서 값을 읽거나 쓰고, 산술연산을 한다.
레지스터
레지스터는 CPU에 있는 매우 작은 메모리 여럿이며, CPU 아키텍쳐에 따라 레지스터의 크기, 종류와 개수가 다르다. 범용 레지스터의 크기에 따라 CPU bit를 정의한다.
즉 32bit CPU는 범용 레지스터의 크기가 32bit이며, 64bit CPU는 범용 레지스터의 크기가 64bit이다. 그리고 이 때 범용 레지스터의 크기를 CPU의 워드 사이즈라고 하며, 이 워드 사이즈는 CPU가 기본적으로 처리하는 데이터의 크기이다.
그리고 레지스터의 경우 한번에 처리할 수 있는 데이터의 양이 수십 비트 밖에 안되는 매우 작은 메모리 이지만, 그 처리 속도는 매우 빠르다.
주 메모리
하지만 이렇게 적은 양의 데이터만 처리할 수는 없기 때문에 큰 크기의 메모리가 필요한데, 이것이 주 메모리, 우리가 흔히 말하는 램(RAM: Random Access Memory)라고 부르는 장치이다. 요즘 사용하는 주 메모리의 크기는 다양한데 대부분 8GB이상의 주 메모리를 사용하는 것 같다. 주 메모리는 레지스터를 구성하는 메모리 반도체 소자보다 값싼 소자 및 회로를 사용하므로 레지스터보다 큰 용량 대비 가격이 저렴하지만, 읽기 쓰기 속도가 100배 이상 차이날 정도로 성능 차이가 심하다.
CPU 레지스터와 주 메모리의 처리 속도 차리
CPU에서 연산을 하려면 주 메모리에서 레지스터로 값을 가져와야 하는데, 레지스터와 주 메모리의 읽기 쓰기(I/O) 속도 차이가 심하므로 주 메모리에서 극심한 병목 현상을 겪게 된다. CPU는 빠른 처리 속도를 가지고 있지만, 주 메모리에서 값을 받아오는 것을 기다리다 보니 처리 속도가 주 메모리의 속도로 하향 평준화가 되는 것이다.
캐시 메모리
첫 단락에서 언급 했듯, 이러한 레지스터와 주 메모리의 I/O 성능 차이를 완화시키기 위해 레지스터와 주 메모리 사이에 캐시 메모리를 도입했다. 캐시 메모리는 레지스터 보다는 메모리 사이즈가 더 크고, 주 메모리 보다는 메모리 사이즈가 작다. 그리고 레지스터와 같이 고속으로 처리할 수 있는 비싼 반도체 소자를 활용해서 빠른 읽기 쓰기가 가능하도록 제작하였다.
캐시 메모리의 동작 예시
그래서 이 캐시 메모리는 부대찌개의 앞접시 처럼, 레지스터가 바로 주 메모리로 접근 하는 것이 아닌 고속의 캐시 메모리에 데이터를 덜어서 가져가도록 하는 것이다. 캐시 메모리는 다음과 같은 시나리오로 동작한다.
- CPU가 1번 주소의 메모리 값을 읽어오고자 한다.
- CPU는 캐시 메모리를 참조해서 1번 주소의 데이터 값이 있는지 확인한다.
- 캐시 메모리에 1번 주소의 데이터가 값이 없다 = 이를 캐시 미스(Cache miss)라고 한다.
- 주 메모리의 1번 주소의 데이터 값을 Copy해서 캐시에 저장한다.
- CPU가 1번 주소의 메모리 값을 다시 읽어오고자 한다.
- CPU는 캐시 메모리를 참조해서 1번 주소의 데이터 값이 있는지 확인한다.
- 캐시 메모리는 1번 주소의 데이터가 값이 있다. = 이를 캐시 히트(Cache hit)라고 한다.
- CPU는 느린 주 메모리 까지 접근할 필요 없니 캐시 메모리에서 1번 주소의 메모리 값을 읽어온다.
주 메모리에 접근할 때 100의 latency가 발생하고, 캐시 메모리에 접근할 때 1의 latency가 발생한다고 했을 때, 같은 값을 한번 불러서 여러번 읽는다면 굉장한 속도 효율을 낼 수 있다.
비슷하게 메모리에 값을 쓰는(Write) 경우도 캐시 메모리에만 값을 쓰는 방식으로 latency를 줄일 수 있다. 그러면 일시적으로 캐시 메모리의 데이터 값과, 주 메모리의 데이터 값이 다른 Memory inconsistency가 발생할 수 있는데 캐시 메모리에서 해당 주소값이 캐시 메모리에서 나가게 되는 경우 주 메모리에 바뀐 내용을 Write하게 된다. 이 정책을 Write back이라고 한다.
이와 달리 Write through라는 정책을 활용하면 메모리에 값을 써야 할 때, 캐시 메모리 뿐만 아니라 주 메모리에도 값을 쓴다. 이렇게 하면 Memory inconsistency가 발생하지 않지만 성능적으로는 느려진다.
스토리지
앞서 이야기한 레지스터, 캐시 메모리, 주 메모리는 전기의 공급이 끊기면 데이터가 사라지는 기억장치들이다. 이와 달리 전기의 공급이 끊겨도 데이터가 남아있는 보조기억장치가 있는데 주로 이들을 스토리지(Storage)라고 부르겠다. 우리에게 친숙한 하드디스크나 SSD와 같은 친구들이 이 스토리지에 해당한다. 이 스토리지는 용량 대비 가격이 매우 싸서 많은 데이터를 저장하기 적합하지만, 읽기 쓰기 속도는 주 메모리 보다도 더 느리다.
메모리 계층구조(Memory Hierarchy)
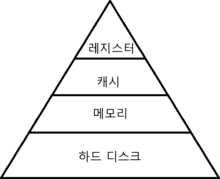
위에서 언급한 저장장치들을 피라미드 형태로 그려놓은 이미지이다. 직접 그리려고 했는데 너무 귀찮은 나머지 위키에서 퍼왔다.
위와 같은 형태를 메모리 계층구조라고 한다. 아래로 갈 수록 저장 공간의 크기가 커진다. 그 이유는 단위 용량 당 메모리 반도체 & 소자 & 구성요소의 가격이 값싸서 그렇다. 그리고 위쪽으로 갈 수록 처리속도가 빨라진다.
이러한 메모리 계층구조를 갖는 컴퓨터를 만드는 이유는 가성비 때문이다. 사실 캐시메모리 등을 구성하는 정적 메모리 소자로만 주 메모리를 만들면 굉장히 빠른 고성능의 컴퓨터를 쓸 수 있지만, 가격이 기하급수적으로 비싸지기 때문에 그렇게 하지않는다. 그렇다고 캐시 메모리를 빼서 가격을 낮추면 처리 속도가 너무 느려진다.
그런데 메모리가 위쪽으로 올라갈 수록 크기가 급격히 작아지는데 이러한 계층구조로 생각보다 꽤 괜찮은 가성비의 속도가 나오는 이유가 무엇일까? 이 이유로는 지역성이라는 소프트웨어의 특징 덕분이다.
지역성(Locality)
메모리 계층구조가 가성비를 가질 수 있는 이유로는 지역성이라는 소프트웨어, 컴퓨터 프로그램의 특징 덕분이다. 그리고 이 지역성은 시간 지역성(Temporal Locality)와 공간 지역성(Spatial Locality)로 나뉜다.
간단하게 이야기 하자면, 시간 지역성은 지금 1번지 메모리에 접근된 적이 있으면 가까운 시일 내에도 1번지 메모리에 접근될 확률이 높다는 것이다. 공간 지역성은 비슷하게 1번지 메모리에 접근된 적이 있으면 2,3번지 메모리에 접근될 확률이 높다는 것이다.
왜 그럴까?
우리가 프로그램을 작성하는 방식을 한번 생각해보자.
만약 CPU가 함수안의 코드를 실행한다고 하면, 그 함수 안에서는 함수의 인자와 지역변수들을 많이 활용할 것이다. 이것이 일단 시간 지역성이다. 그리고 for-loop와 같은 반복문의 경우 반복문 instruction 들이 계속 반복되므로 이 경우에도 시간 지역성이 만족된다.
그리고 배열같은 경우도 반복문으로 배열 순회를 한다던지 하면 arr[1]에 접근된 뒤 곧이어 arr[2]를 접근할 확률이 높을 것이다. 이러한 이유로 공간 지역성도 만족된다.
따라서 이런 특성 때문에 캐시 메모리와 같이 매우 작은 크기로도 꽤 괜찮은 성능 향상을 이룰 수 있다. 그리고 이런 지역성을 고려해서 캐시 메모리의 스케쥴링도 설계되어 있다.
LRU Cache scheduling 알고리즘과 Cache block size와 같은 내용들을 추가적으로 언급해야 하는데, 나중에 다시 써 보도록 하겠다.
레퍼런스
https://ko.wikipedia.org/wiki/%EB%A9%94%EB%AA%A8%EB%A6%AC_%EA%B3%84%EC%B8%B5_%EA%B5%AC%EC%A1%B0
'개발 & CS 지식' 카테고리의 다른 글
| css flexbox 컨셉으로 html element 크기 비율로 조정하기 (0) | 2020.12.29 |
|---|---|
| 컴퓨터에서 정수 표기법 (2의보수, 1의보수, 부호와 크기) (0) | 2020.11.05 |
| Linux Mint에서 add-apt-repository 명령어 Malformed repository name 에러나는 경우 해결 (0) | 2020.10.21 |
| 클립보드 데이터 형식과 API들 (0) | 2020.10.04 |
| 도커 컨테이너(Docker Container)와 개요 (0) | 2020.09.25 |