I prefer web hacking challenges, so at the first I tried web problem.
There was only one web challenge.
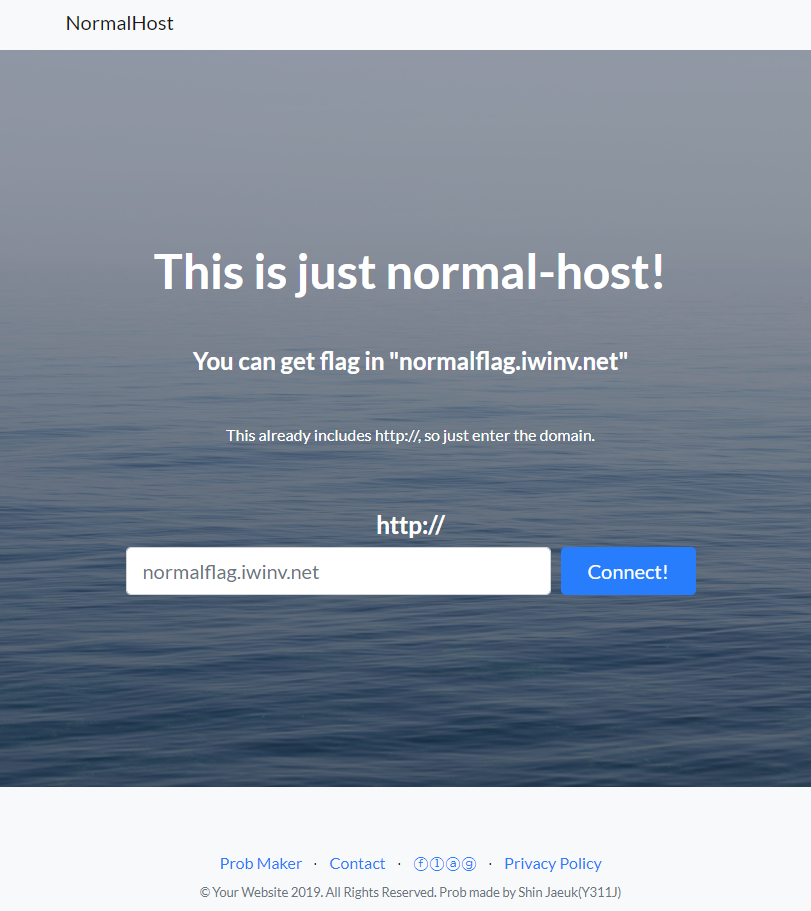
When I clicked link, I can see a just simple single page.
There is nothing interesting, although I inspect the html source code.
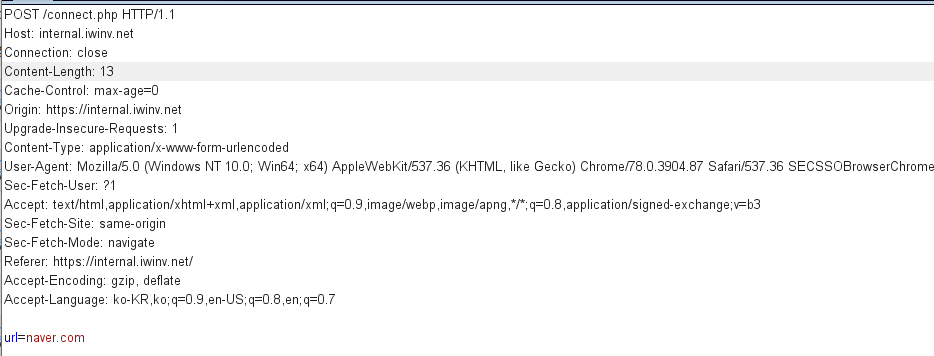
We should enter the "normalflag.iwinv.net" link, via the page shown above.
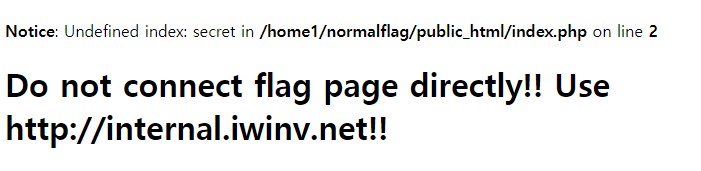
I tried to enter the "normalflag.iwinv.net" link directly, and saw that warning documents.
I just typed the target host domain on the gate page,
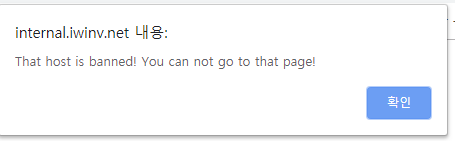
the alert modal appeared, I assume the host string is blacklisted.
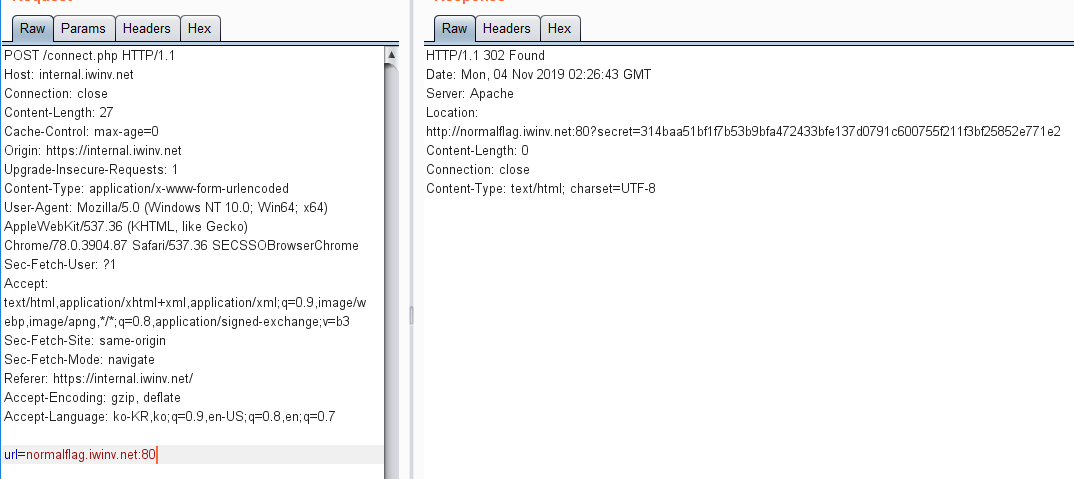
I analysis the http packet with burp suite.
When I typed "naver.com" to hostname field,
the http request is like that.
response code is 302 redirection with some tailing "?secret=" query parameter.
I just concatenate the target host with that secret parameter, and try to connect directly,
They said, it is not intended solving direction. Whenever we enter the host, the secret parameter value changes. So, I assume the secret parameter is a kind of one time ticket with randomly created.
I tried more with some url fragment(#123 like that) or tailng path like host.com/blur/blur but it doesn't work.
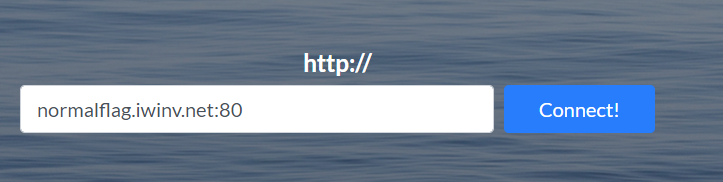
When I concatenated port number :80 to the target hostname, it looks working!
I got the flag!!
한글 풀이
Newbie CTF라는게 있길래 참여해봤다.
한국팀 주최 대회였다.
웹쟁이 답게 웹 문제부터 확인을 했는데, 한문제 밖에 없어서 조금 아쉽..
링크로 들어가면 간단한 페이지가 하나 나온다.
소스보기를 봐도 별 다른건 없는듯.
normalflag.iwinv.net라는 링크를 들어가야하는데, 저 페이지를 통해서 들어가야 하는 듯 하다.
그냥 링크로 들어가니 저런 경고문이 뜬다.
그렇다고 그냥 링크를 치고 들어가려니,
호스트가 필터링 된 듯.
원리가 어떤식인가 싶어서 버프슈트를 한번 잡아보았다.
네이버로 해서 잡아보니,
요런 요청이 가고,
302응답으로 Redirection이 되는데, 뒤에 ?secret=라는 파라메터가 붙어서 온다.
저기있는 secret을 띠어서 flag url에 박아서 보내보니
의도된 풀이가 아니라고 한다. secret이 요청 때 마다 바뀌는 걸로 봐서, 그때그때 발급하는 티켓 같은 방식인 것으로 보인다.
N, M, T값이 50으로 작은편이므로, 원판을 죄다 돌려버리고 돌릴때 마다 다 체크를 한다고 해봅시다.
1번 돌릴때 마다 인접한 원판 수들을 체크를 해야하는데, 최대 원판에 쓰인 수의 개수는 N * M개 이므로 최대 50*50 = 2500개입니다.
2500개의 수를 50번 확인한다고 하면 125,000번으로 12만 5천번 정도됩니다.
그리고 그 때 마다 원판위의 숫자들을 shift한다고 하면, 모든 원판의 수를 다 shift하고 그 양이 50과 같이 큰 값이라 하면
50^4 = 6,250,000으로 625만번입니다. shift하는 것을 한번씩 여러번 반복하는 식으로 매우 대충 구현한다는 가정하에 대충 이정도 값이 나옵니다.
그런데 shift하는 것은 한번에 점프뛰는 방식으로도 가능하기 때문에 이정도까지도 안나옵니다.
고로 결론은, 그냥 그대로 따라하는 시뮬레이션 방식으로 구현해도 충분히 시간안에는 들어오는 크기의 N,M,T 값이라는 것입니다.
(대충 1억번 연산에 1초 정도 걸린다고 봅니다.)
구현 전략
원판 돌리는 연산을 간편하게 하기 위해서 bias라는 배열을 따로 두고, [원판][위치] 의 값을 읽거나 쓸 때에는 별도의 getter, setter 함수를 만들어서 코드를 작성해 보았습니다.
이녀석의 원리를 조금 설명드려 보자면 예를들어 다음과 같은 원판이 있다고 칩시다. 한 원판에 숫자가 4개 쓰여있으니 M=4가 됩니다.
12시 부터 시계방향으로 숫자를 읽는다면 1,2,3,4 가 되겠지요?
이 원판을 시계방향으로 90도 돌리면 다음과 같은 모양이 됩니다.
마찬가지로 12시 부터 읽는다면 4,1,2,3이 됩니다.
이를 잘라서 평평하게 핀다고 생각해봅시다.
그러면 초기의 1,2,3,4는 다음 모양과 같게 나옵니다.
그리고 시계방향으로 90도 돌린 4,1,2,3은 다음과 같게 나옵니다.
실제로 C언어 배열에는 위와 같이 연속된 메모리에 값이 저장이 되겠지요. 근데 그렇다면 한번 원판을 돌릴 때 마다 4개(M개)의 칸의 값을 모두 바꾸어 주어야 하는데, 발상을 조금 바꾸어봅시다.
값은 맨 처음 그대로 1,2,3,4로 저장을 하되, 읽는 순서만 바꾸는 거죠.
처음 1,2,3,4가 나오기 위해서는 인덱스 읽는 순서를 0,1,2,3으로 읽고, 시계방향으로 90도 돌린 경우는 인덱스를 3,0,1,2의 순서로 읽는것입니다.
그러면 아까처럼 값을 바꾸는 경우와 똑같은 값이 나오게 됩니다.
마찬가지로, 반시계방향으로 90도 돌린 경우는 인덱스를 1,2,3,0의 순서로 읽게 되겠지요?
따라서 원판이 시계방향으로 돌리게 되면 bias값에 -1을 해 줄것이고, 반시계 방향으로 돌리게 되면 bias값에 +1를 해줍니다.
시계방향으로 한번 돌리고 반시계 방향으로 한번 돌리면 결론적으로 원래 자리로 돌아오게 되는데 bias값에는 이러한 점도 적용이 되게 됩니다.
즉 bias값은 맨 처음 값을 몇 번째 인덱스부터 읽을 것인지를 나타내게 되는 것이지요.
하지만 bias값이 4보다 크거나 음수가 나타날 수 있으니, 이 bias값이 0이상 3이하(M-1)의 값만 나오게 하도록 모듈러(나머지)연산을 해 줍니다.
음수의 경우 모듈러 연산을 해도 음수가 나오기 때문에 4(M값)만큼을 더해서 0이상 3이하의 값이 나오게 되는 것입니다.
디버깅을 위해서 dump함수도 작성했는데, 활성화 하기 위해서는 dump 함수의 return 값을 제거하고 사용하시면 됩니다.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define endl '\n'
#define DEL 99999
int num[55][55];
int bias[55];
int N, M, T;
typedef pair<int, int> pii;
void dump(const char[]);
int get_num(int i, int j) {
//i번째 원판의 j번째 위치 녀석 값 가져오기
j += bias[i];
while (j < 0) {
j += M;
}
j %= M;
return num[i][j];
}
void set_num(int i, int j, int v) {
//i번째 원판의 j번째 위치 녀석 값을 v로 셋팅
j += bias[i];
while (j < 0) {
j += M;
}
j %= M;
num[i][j] = v;
}
void process() {
//인접수 날리고, 값 조정 한번에 하는 함수
bool changed = false;
vector<pii> del; //지울 수 좌표들 모음
del.clear();
//같은 원판 사이에 인접한 수들 찾아내기
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
int a = get_num(i, j);
int b = get_num(i, j + 1);
if (a != DEL && b != DEL && a == b) {
del.push_back({ i,j });
del.push_back({ i,j + 1 });
changed = true;
}
}
}
//다른 원판 사이에 인접한 수들 찾아내기
for (int i = 0; i + 1 < N; i++) {
for (int j = 0; j < M; j++) {
int a = get_num(i, j);
int b = get_num(i + 1, j);
if (a != DEL && b != DEL && a == b) {
del.push_back({ i, j });
del.push_back({ i + 1, j });
changed = true;
}
}
}
//지울 녀석들 모아서 지우기
for (auto p : del) {
set_num(p.first, p.second, DEL);
}
dump("지운뒤");
//지운 수가 없으면 계속 진행
if (changed) return;
int cnt, sum;
cnt = sum = 0;
//지워지지 않은 수와, 그 수들의 총합 을 구함
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
if (num[i][j] != DEL) {
cnt++;
sum += num[i][j];
}
}
}
//남은 수들이 평균보다 크면 -1, 작으면 +1 시킴.
//나누기를 안쓰는 이유는 정수 소수점 잘리는 부분 때문
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
if (num[i][j] != DEL) {
if (num[i][j] * cnt > sum) {
num[i][j]--;
}
else if (num[i][j] * cnt < sum) {
num[i][j]++;
};
}
}
}
dump("덧뺄샘이후");
}
int main() {
cin >> N >> M >> T;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
cin >> num[i][j];
}
}
while (T--) {
//회전 시킬 값들 받기
int x, d, k;
cin >> x >> d >> k;
int v = x;
int shift = k * (d == 0 ? -1 : +1);
dump("돌리기전");
while (v <= N) {
//bias 배열에다가 값을 더하는식으로, 회전시킴
bias[v-1] += shift;
v += x;
}
dump("돌린뒤");
//인접수 지우고 하는 처리들을 여기서 함
process();
}
//남은 수 다 더해서 출력
int ans = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
if (num[i][j] != DEL) {
ans += num[i][j];
}
}
}
cout << ans << endl;
}
void dump(const char str[]) {
#ifndef WIN32
return;
#endif
puts(str);
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
cout << get_num(i, j) << ' ';
}
cout << endl;
}
cout << "============================" << endl;
}
이번 주말에는 아무것도 없는 줄 알았다가, 킥스타트 Remind 메일을 보고 토요일 밤에 구글 킥스타트가 있는것을 알고 참여했다.
구글 킥스타트는 구글 코드잼과 비슷한 대회인데, 다른 점은 각각의 라운드가 독립적인 하나 뿐이라는 것.
구글 코드잼은 예선전(Qualification Round)부터 Round 1,2,3이후 월드파이널 온사이트 대회로 넘어가는 방식으로 각 단계에서 사람수를 줄여가는 식의 서바이벌 방식의 대회라고 볼 수 있다.
킥스타트는 대학생들 대상으로 채용을 목적으로하는 대회로, 각각의 독립 라운드가 날짜별로 시간대별로 포진되어있다.
A,B,C 등등과 같은 방식으로 라운드를 구분한다.
따라서 하려는 라운드가 우리 한국시각으로는 새벽이더라도, 다른 한국시각으로 낮이나 저녁시간대인 다른 대회를 참여하면 되는 것이다.
결론부터 말하면 385등으로 총 3문제 중, 2.5문제를 풀었다.
뭔가 거의 다 푼 것 같아서 기분은 좋다.
3번째 문제 Hidden Test case는 날려먹엇는데, 풀이가 올라왔으니 차근차근 읽어봐야 할듯.
1번 문제 Book Reading은 대충 설명해보면, 배수를 찾는 문제이다.
1~N 페이지인 책 중 M개의 페이지가 찢겨져 나가있고, Q명의 독자는 각각 자신이 원하는 수의 배수에 해당하는 책 페이지만 읽는다 했을때, 독자들이 읽은 페이지의 총 개수를 구하면 된다.
책이 찢겨지지 않았다고 했을때는, 배수만 구해서 죄다 더해버리면 된다. 다만 찢긴 페이지를 어떻게 처리하냐가 관건이다.
Visible을 맞추기 위해서는 각각 독자별로 찢겨진 페이지에 얼마나 해당되는지만 체크하면 된다. Brute Force로 풀리는 크기로 N,M,Q가 1000이하이다.
Visible을 맞추기 위한 코드이다.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define endl '\n'
ll solve() {
int N, M, Q;
scanf("%d%d%d", &N, &M, &Q);
ll ans = 0;
vector<int> torn(M);
vector<int> reader(Q);
for (int i = 0; i < M; i++) {
cin >> torn[i];
}
for (int i = 0; i < Q; i++) {
cin >> reader[i];
ans += (ll)N / reader[i];
}
for (auto tt : torn) {
for (auto rdr : reader) {
if (tt % rdr == 0) {
ans--;
}
}
}
return ans;
}
int main() {
int tc;
scanf("%d", &tc);
for (int t = 1; t <= tc; t++) {
printf("Case #%d: %lld\n", t, solve());
}
}
Hidden을 맞추기 위해서는 좀 더 효율적인 코드가 필요하다.
찢겨진 페이지들을 소인수 분해한 뒤, 약수를 모두 다 구해서 해당 약수들에 cnt배열 값을 1씩 증가시키는 방식으로 독자를 쿼리를 최적화 해 보았다. 될지 안될지는 긴가 민가 했는데, 대충 통한듯.
소수들은 에라토스테네스의 채를 이용해서 구했다.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define endl '\n'
#define MAXN 100005
bool sieve[MAXN]; //false == prime
int cnt[MAXN];
vector<int> primes;
bool is_prime(int n) {
if (n < 2) return false;
if (n == 2) return true;
for (int i = 2; i*i <= n; i++) {
if (n % i == 0) return false;
}
return true;
}
void get_sieve() {
sieve[0] = sieve[1] = true;
for (int n = 2; n < MAXN; n++) {
if (sieve[n] == false && is_prime(n)) {
int base = n * 2;
while (base < MAXN) {
sieve[base] = true;
base += n;
}
}
}
for (int i = 2; i < MAXN; i++) {
if (sieve[i] == false) {
primes.push_back(i);
}
}
}
void factorize(int n, vector<pair<int, int>>& factors) {
while (n > 1) {
for (int prime : primes) {
if (prime > n) break;
int cnt = 0;
while (n % prime == 0) {
n /= prime;
cnt++;
}
if (cnt) {
factors.push_back(make_pair(prime, cnt));
}
}
}
}
void get_divisors(int n, vector<pair<int, int>>& factors, int k) {
if (k == (int)factors.size()) {
cnt[n]++;
//cout << "got divisor = " << n << endl;
return;
}
get_divisors(n, factors, k + 1);
int exp = factors[k].second;
for (int dec = 1; dec <= exp; dec++) {
factors[k].second -= dec;
n /= factors[k].first;
get_divisors(n, factors, k + 1);
factors[k].second += dec;
}
n *= pow(factors[k].first, exp);
}
ll solve() {
memset(cnt, 0, sizeof(cnt));
int N, M, Q;
scanf("%d%d%d", &N, &M, &Q);
ll ans = 0;
vector<int> torn(M);
vector<int> reader(Q);
for (int i = 0; i < M; i++) {
cin >> torn[i];
}
for (int i = 0; i < Q; i++) {
cin >> reader[i];
ans += (ll)N / reader[i];
}
for (int i = 0; i < M; i++) {
vector<pair<int, int>> factors;
factors.clear();
factorize(torn[i], factors);
get_divisors(torn[i], factors, 0);
}
for (auto rdr : reader) {
ans -= cnt[rdr];
}
return ans;
}
int main() {
get_sieve();
int tc;
vector<pair<int, int>> factors;
scanf("%d", &tc);
for (int t = 1; t <= tc; t++) {
printf("Case #%d: %lld\n", t, solve());
}
}
2번 문제는 약간 수학적인 문제같이 생겻는데, N개의 A숫자가 있고 숫자 M이 있을때
(A1 ^ k) + (A2 ^ k) + ... + (An ^ k) <= M을 만족하는 최대 k를 구하면 된다.
Visible은 모든 k에 대하여 다 해보고 최대 값을 구하는 완전탐색으로 풀린다.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define endl '\n'
ll A[1003];
int bitmap[20];
ll solve() {
memset(bitmap, 0, sizeof(bitmap));
ll ans = -1;
int N;
ll M;
cin >> N >> M;
ll sum = 0;
for (int i = 0; i < N; i++) {
cin >> A[i];
}
for (ll k = 0; k <= 1000; k++) {
ll ss = 0;
for (int i=0; i < N; i++) {
ll& a = A[i];
ss += (a^k);
if (ss > M) break;
}
if (ss <= M) {
ans = max(ans, k);
}
}
return ans;
}
int main() {
int tc; cin >> tc;
for (int t = 1; t <= tc; t++) {
printf("Case #%d: %lld\n", t, solve());
}
}
Hidden은 좀더 효율적인 방법이 필요한데, 어차피 10^16이면 50비트 남짓이라는 것을 이용해서, 받는 A 숫자들을 비트별로 개수를 다 세어놓는다.
해당 비트 사용수가 과반수이면, 즉 N/2보다 크면, k의 해당 비트를 1로 해서 비트 들을 Inverse시켜주는 식으로 한번 전처리 한뒤,
M과 지금 다 합친 값과 여유분을 계산을 해서 , k의 가장 큰 bit를 xor해서 inverse해줘도 되는 경우 bit를 1로 set하는 식으로 구해보았다.
멍청하게 bitmap 배열을 20으로 잡아서(10^20을 생각) 런타임 에러가 막 났었는데 2^50이니 50이상 잡았어야 했다.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define endl '\n'
ll A[1003];
int bitmap[60];
ll solve() {
memset(bitmap, 0, sizeof(bitmap));
ll ans = 0;
int N;
ll M;
cin >> N >> M;
ll sum = 0;
for (int i = 0; i < N; i++) {
cin >> A[i];
sum += A[i];
for (int j = 0; j <= 50; j++) {
if (A[i] & (1LL << j)) {
bitmap[j]++;
}
}
}
for (int i = 0; i <= 50; i++) {
if (bitmap[i] * 2 >= N) {
ans |= (1LL << i);
sum += (1LL << i) * (N - bitmap[i] * 2);
}
}
//if (sum > M) return -1LL;
for (int i = 50; i >= 0; i--) {
if ((1LL << i) & ans) continue;
ll diff = M - sum; //여유분
ll cost = (1LL << i) * (N - bitmap[i] * 2);
if (cost <= diff) {
ans |= (1LL << i);
sum += cost;
}
}
if (sum > M) return -1LL;
return ans;
}
int main() {
int tc; cin >> tc;
for (int t = 1; t <= tc; t++) {
printf("Case #%d: %lld\n", t, solve());
}
}
3번 문제는 교대근무를 하는 2명의 직원이 있고, 각 근무시간은 최소 한명이상 근무해야하며, 근무 시 얻는 Happiness를 합한 값이 각각 H를 넘는 경우의 수를 구하는 그런문제다.
문제를 딱 보고 어렵다 생각했는데 Visible N값이 12로 완전탐색을 조져도 될 것이라는 생각이 들었다.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define endl '\n'
ll A[22], B[22];
ll solve() {
ll ans = 0;
int N;
ll H;
cin >> N >> H;
for (int i = 0; i < N; i++) {
cin >> A[i];
}
for (int i = 0; i < N; i++) {
cin >> B[i];
}
ll AH, BH;
for (int bit = 1; bit < (1 << N); bit++) {
AH = 0;
//BH = 0;
for (int i = 0; i < N; i++) {
if (bit & (1 << i)) {
AH += A[i];
}
}
if (AH < H) continue;
for (int bbit = 1; bbit < (1 << N); bbit++) {
BH = 0;
for (int i = 0; i < N; i++) {
if (bbit & (1 << i)) {
BH += B[i];
}
}
if (BH < H) continue;
if ((bit | bbit) != ((1 << N) - 1)) continue;
ans++;
}
}
return ans;
}
int main() {
int tc;
cin >> tc;
for (int t = 1; t <= tc; t++) {
printf("Case #%d: %lld\n", t, solve());
}
}
Hidden으로 N=20은 도저히 어떻게 해야할 지 생각이 안나서 스킵해놓은 상태이다. 이따가 풀이보고 공부해봐야겠다.