Rotation시키는 것은, 돌아가는 원판에 있는 숫자들을 다 저장해놓고, 한칸씩 더 이동시켜서 다시 넣는 방식으로 했으며
왼쪽위 오른쪽위, 오른쪽아래, 왼쪽아래 꼭지점을 기준으로
해당 꼭지점에 다다를때 이동방향을 바꾸는 식으로 구현해보았습니다.
#include <bits/stdc++.h>
using namespace std;
typedef pair<int, int> pii;
int A[55][55];
typedef struct _Rot {
int r, c, s;
} Rot;
Rot rot[10];
int N, M, K;
int ans;
void get_input();
bool used[10];
int order[10];
void copy(int A[][55], int B[][55]);
const int dx[] = { +0, +1, +0, -1 };
const int dy[] = { +1, +0, -1, +0 };
void _rotate(int B[][55], int row, int col, int rad) {
vector<int> val;
int x = row - rad;
int y = col - rad;
int cnt = rad * 8;
set<pii> check;
check.insert(make_pair(row + rad, col + rad));
check.insert(make_pair(row - rad, col + rad));
check.insert(make_pair(row + rad, col - rad));
int k = 0;
for (int i = 0; i < cnt; i++) {
val.push_back(B[x][y]);
x += dx[k];
y += dy[k];
if (check.find(make_pair(x, y)) != check.end()) {
k++;
}
}
k = 0;
x = row - rad;
y = col - rad;
x += dx[0];
y += dy[0];
for (int i = 0; i < cnt; i++) {
B[x][y] = val[i];
x += dx[k];
y += dy[k];
if (check.find(make_pair(x, y)) != check.end()) {
k++;
}
}
}
void rotate(int B[][55], int row, int col, int rad) {
for (int i = 1; i <= rad; i++) {
_rotate(B, row - 1, col - 1, i);
}
}
void dfs(int p) {
if (p < K) {
for (int i = 0; i < K; i++) {
if (used[i] == false) {
used[i] = true;
order[p] = i;
dfs(p + 1);
used[i] = false;
}
}
}
else {
//do simulation
int B[55][55];
copy(B, A);
for (int i = 0; i < K; i++) {
auto& o = rot[order[i]];
rotate(B, o.r, o.c, o.s);
}
for (int i = 0; i < N; i++) {
int sum = 0;
for (int j = 0; j < M; j++) {
sum += B[i][j];
}
ans = min(ans, sum);
}
}
}
int main() {
ans = 987654321;
get_input();
dfs(0);
cout << ans << endl;
}
void get_input() {
cin >> N >> M >> K;
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++)
cin >> A[i][j];
for (int i = 0; i < K; i++) {
auto& R = rot[i];
cin >> R.r >> R.c >> R.s;
}
}
void copy(int A[][55], int B[][55]) {
for (int i = 0; i < N; i++)
for (int j = 0; j < M; j++) {
A[i][j] = B[i][j];
}
}
B번 문제입니다. 사과의 풍미(flavor) 값은 연속된 수열 값으로 나타납니다. 전체 값 중에서 사과 하나를 뺏을 때 차이가 가장 적을려면, 전체 값 중에 절대값이 가장 작은 것을 하나 빼버리면 됩니다.
O(N)으로 해결할 수 있습니다.
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
typedef long long ll;
typedef pair<int, int> pii;
int main() {
int N, L;
cin >> N >> L;
int S = (N - 1) * N / 2 + N * L;
int dect = 987654321;
for (int i = 0; i < N; i++) {
int cand = i + L;
if (abs(cand) < abs(dect)) {
dect = cand;
}
}
cout << (S - dect) << endl;
}
(전체) - (C로 나누어 떨어지는 수) - (D로 나누어 떨어지는 수) + (C와 D 둘다 나누어 떨어지는 수)
가 됩니다.
C와 D 둘다 나누어 떨어지는 수는 C와 D의 LCM(최소공배수)으로 나누어 떨어지는 수와 같습니다.
C와 D의 최소 공배수는 C*D / gcd(C, D)와 같습니다.
gcd(C, D)는 C와 D의 최대공약수를 뜻합니다.
#include <bits/stdc++.h>
#include <algorithm>
using namespace std;
#define endl '\n'
typedef long long ll;
typedef pair<int, int> pii;
template<class T>
T gcd(T a, T b)
{
if (b == 0) return a;
a %= b;
return gcd(b, a);
}
int main() {
ll A, B, C, D;
cin >> A >> B >> C >> D;
ll total = B - A + 1;
ll Cdiv = B / C - ((A - 1) / C);
ll Ddiv = B / D - ((A - 1) / D);
ll LCM = C * D / gcd(C, D);
ll CDdiv = B / LCM - ((A - 1) / LCM);
ll ans = total - Cdiv - Ddiv + CDdiv;
cout << ans << endl;
}
E번 문제입니다. 문제 내용을 잘못 이해해서 좀 해맸었는데, 일단 N개의 vertex로 shortest path = 2인 pair를 최대한 많이 만드는 구성을 한번 생각해봤습니다.
N=7이라 한다면, 대충 위와 같이 생겼을 때 가장 많은 shortest path = 2인 쌍이 생깁니다. 1을 제외한 모든 조합들이 가능한거죠.
즉 //(\dbinom{6}{2}//)개 만큼 생깁니다.
N에 대하여 일반화를 하면 //(\dbinom{N-1}{2}//)가지가 나오는 것이죠. 요렇게 나오는 경우가 최대 경우입니다.
따라서 //(K > \dbinom{N-1}{2} //)이면 불가능한 경우입니다.
그렇다면 저 최대값 이하의 값은 다 만들수가 있느냐?
이에 대한 답은 Yes입니다. 위 그림에서 예를 들어 4와 5를 연결해버리면, 4에서 5로 가는 최단거리가 1이 되어서, 만족하는 쌍의 수가 하나 줄게 됩니다. 그리고 그 추가된 Edge는 다른 pair들에는 전혀 영향을 끼치지 않죠. 이런식으로 하나하나씩 줄여서 K값을 0으로 만들수도 있습니다.
따라서 N값에 따라서 0~최대값까지 죄다 만들 수 있는 것이죠. 이 범위 안에 들어있다면 저런 형태의 graph를 리턴하고, 그렇지 않다면 불가능하다라고 출력하면 됩니다.
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
typedef long long ll;
typedef pair<int, int> pii;
int main() {
int N, K;
cin >> N >> K;
int maxi = (N - 1)*(N - 2) / 2;
if (K > maxi) {
cout << -1;
return 0;
}
int M = N - 1;
int diff = maxi - K;
cout << (M + diff) << endl;
for (int i = 0; i < M; i++) {
cout << 1 << ' ' << i + 2 << endl;
}
int src = 2;
int dst = 3;
for (int i = 0; i < diff; i++) {
cout << src << ' ' << dst << endl;
dst++;
if (dst == N + 1) {
src++;
dst = src + 1;
}
}
}
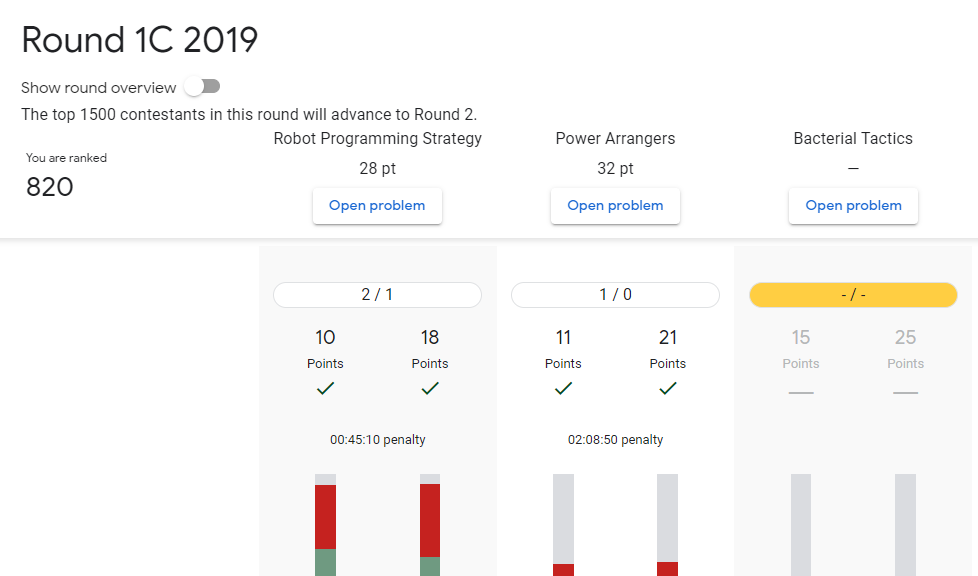
이번 라운드는 오후 6시부터 8시 반까지 진행되었는데, 8시 30분부터 불꽃 축재를 보러 가야하기 때문에 사실상 8시까지만 문제를 풀 수 있었다.
최대한 집중해서 문제를 풀었는데, 배점을 확인해서 난이도가 1 < 2 < 3 인것을 알고 1번부터 풀이를 시작했다.
- Robot Programming Strategy
문제를 읽어보고 토너먼트 방식이라는 점에 꽤나 복잡한 문제라고 생각해보았는데, 사실 모든 적들을 다 이길 수 있는 조합을 만들어 내면 된다.
Strategy가 끝에 다달으면 다시 Cyclic하게 순환된다는 점에 유의해야 한다. Brute-Force로 Visible만 풀려고 했는데, 생각보다 N값이 작아서 Hidden 도 풀렸다.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
set<string> enemy;
int main() {
int tc; cin >> tc;
for (int t = 1; t <= tc; t++) {
int A;
cin >> A;
enemy.clear();
string ans = "";
bool ok = true;
for (int i = 0; i < A; i++) {
string s; cin >> s;
enemy.insert(s);
}
for (int i = 0; i < 500; i++) {
int R, S, P;
R = S = P = 0;
for (auto s : enemy) {
char c = s[i % (int)s.length()];
if (c == 'R') R++;
else if (c == 'S') S++;
else if (c == 'P') P++;
}
int C = 0;
C += R > 0 ? 1 : 0;
C += S > 0 ? 1 : 0;
C += P > 0 ? 1 : 0;
if (C == 3) {
ok = false;
break;
}
else if (C == 1) {
if (R) ans += "P"; //바위에는 보
else if (S) ans += "R"; //가위에는 바위
else ans += "S"; //보에는 가위
break;
}
else {
//vector<string> victim;
if (R == 0) { //보와 가위
ans += "S";
//i번째에 P인놈들 삭제
for (auto s : enemy) {
char c = s[i % (int)s.length()];
if (c == 'P') {
enemy.erase(s);
//victim.push_back(s);
}
}
}
else if (S == 0) {
ans += "P"; //바위와 보
//i번째에 R인놈들 삭제
for (auto s : enemy) {
char c = s[i % (int)s.length()];
if (c == 'R') {
enemy.erase(s);
//victim.push_back(s);
}
}
}
else if (P == 0) {
ans += "R"; //가위와 바위
//i번째에 S인놈들 삭제
for (auto s : enemy) {
char c = s[i % (int)s.length()];
if (c == 'S') {
enemy.erase(s);
//victim.push_back(s);
}
}
}
//for (auto s : victim) {
// enemy.erase(s);
//}
//victim.clear();
}
}
printf("Case #%d: %s\n", t, ok == false ? "IMPOSSIBLE" : ans.c_str());
}
}
- Power Arrangers
Permutation 순열 관련된 문제였다. 백준에서 K-번째 시리즈를 풀이하면서 대충 풀이가 영감이 왔는데 풀이는 다음과 같다.
나타난 순열들의 첫번째 글자들이 나타난 횟수를 모두 센다 -> 다 4!번(24) 나타나고 하나만 23번 나타난다. 그러면 23번 나타난 녀석이 첫번째 글자다.
23번 나타난 녀석들을 다시 확인해보면 나머지는 다 3!번(6) 나타나고 하나는 5번 나타난다. 그러면 두번째 글자를 알아낼 수 있다.
6번 나타난 녀석은 나머지는 2!번(2) 나타나고, 하나는 1번 나타난다. 세번째 글자는 1번 나타난 녀석이다.
마지막에는 1번 나타나게 되는데, 0번 나타난 녀석이 4번째 글자고 남는녀석이 5번째 글자가 된다.
Python으로 작성해보려다가 답답해서 다시 C++로 작성했다. Visible만 맞추고 갈려고 했는데 Hidden 도 맞는 솔루션이었다.
디버깅이 까다로웟는데, 파일 입출력으로 로그를 찍어서 확인하면서 디버깅했다.
#include <bits/stdc++.h>
using namespace std;
int value[] = {23, 5, 1, 0};
#define endl '\n'
int main() {
// ofstream fout("output.txt");
int T, F;
setbuf(stdout, NULL);
setbuf(stdin, NULL);
cin >> T >> F;
for (int t=1; t<=T; t++) {
set<int> left;
left.clear();
left.insert(0);
left.insert(1);
left.insert(2);
left.insert(3);
left.insert(4);
vector<int> index[5];
vector<int> ans;
int cnt[5];
ans.clear();
memset(cnt, 0, sizeof(cnt));
for (int i=0; i < 5; i++) index[i].clear();
for (int i=1; i <=595; i+=5) {
cout << i << endl;
string s;
cin >> s;
char c = s[0];
cnt[c-'A']++;
index[c-'A'].push_back(i);
}
int idx = 0;
for (int i=0; i < 5; i++) {
if (cnt[i] == value[0]) {
idx = i;
break;
}
}
// fout << "CNT = {" << cnt[0] << "," << cnt[1] << "," << cnt[2] << "," <<cnt[3] << "," <<cnt[4] << "}" << endl;
ans.push_back(idx);
left.erase(idx);
// fout << idx << endl;
vector<int> next;
for (int kk = 1; kk <4; kk++) {
next.clear();
for (int q : index[idx]) {
next.push_back(q+1);
}
memset(cnt, 0, sizeof(cnt));
for (int i=0; i < 5; i++) index[i].clear();
for (auto i : next) {
cout << i << endl;
string s;
cin >> s;
// if (kk == 2) {
// fout << "query = " << i << endl;
// fout << s << endl;
// }
char c = s[0];
cnt[c-'A']++;
index[c-'A'].push_back(i);
}
for (int i=0; i < 5; i++) {
if (cnt[i] == value[kk] && left.find(i) != left.end()) {
idx = i;
break;
}
}
ans.push_back(idx);
left.erase(idx);
// fout << "IDX = " << idx << endl;
// fout << "CNT = {" << cnt[0] << "," << cnt[1] << "," << cnt[2] << "," <<cnt[3] << "," <<cnt[4] << "}" << endl;
}
if (left.size() == 1) {
for (auto v : left) {
ans.push_back(v);
}
}
//ans.push_back(10 - ss);
string ans_str = "";
for (int a : ans) {
ans_str += (char)(a + 'A');
}
cout << ans_str << endl;
string res;
cin >> res;
if (res[0] == 'N') return 0;
}
}
컴공 학부 전공과목 운영체제 수업에서 프로세스 스케쥴링을 배울 때, MIN 알고리즘이었나, 이름은 정확하게 기억이 안나는데 그런 알고리즘 이 하나있었다.
특징이라고 하면, 지금 멀티탭 스케줄링과 같이, 제한된 리소스에 순차적으로 프로세스들을 실행을 할 때, 멀티탭에서 빼는 것 처럼, 메모리에 로드된 프로세스를 제거하는 횟수를 최소화 하는 알고리즘 중, 실제로 최적이라고 수학적으로 증명된 스케쥴링 기법이다.
하지만, 이 알고리즘을 사용하려면 제약 조건이 하나 있는데, 앞으로 미래에 프로세스가 어떤것이 먼저 실행될 것인지를 전부 알아야 한다는 점이다. 따라서 성능 측정에서만 사용한다고 들었다.
요놈 알고리즘의 특징은, 프로세스를 제거해야 하는 상황일 때에는, 앞으로 사용되기 까지 가장 오래 걸리는 프로세스를 제거하는 식으로 동작한다. 앞으로 사용되지 않는 프로세스라면 우선순위 1순위로 제거될 것이다.
#include <bits/stdc++.h>
using namespace std;
vector<int> O[101];
int ptr[101];
vector<int> A;
set<int> tap;
int main() {
int N, K;
cin >> N >> K;
for (int i = 0; i < K; i++) {
int t;
cin >> t;
A.push_back(t);
O[t].push_back(i);
}
int ans = 0;
for (int i = 0; i < K; i++) {
auto cur = A[i];
if (tap.size() >= N && tap.find(cur) == tap.end()) {
//should remove
int victim, val;
victim = -1, val = 0;
for (auto& t : tap) {
if (O[t].size() <= ptr[t]) {
victim = t;
break;
}
if (val < O[t][ptr[t]]) {
val = O[t][ptr[t]];
victim = t;
}
}
ans++;
tap.erase(victim);
}
ptr[cur]++;
tap.insert(cur);
}
cout << ans << endl;
return 0;
}
최근에 위를 골랏느냐, 아래를 골랐느냐에 따라서 다음 고를 수 있는 상태가 바뀌게 되므로, 2차원 DP 배열로 풀 수 있습니다.
DP 식은
dp[x][status] -> x번째 열 이후 스티커를 다 처리했고, 해당 열의 스티커의 상태가 status가 되었을 때 최대 가치
대충 이러한 정의가 될 것입니다.
자세한 내용은 코드를 첨부합니다.
#include <bits/stdc++.h>
using namespace std;
#define UP 0 //arr에선 위에위치, dp에선 위에것만 선택 가능할 시
#define DOWN 1
#define BOTH 2
int dp[100000][3]; //시작 x좌표와 선택할 수 있는 상태
int arr[100000][2];
int n;
int solve(int len, int stat) {
if (len < 0 or len >= n or stat < 0 or stat >= 3) return 0;
if (dp[len][stat] != -1) return dp[len][stat];
int ans = 0;
if (stat != DOWN) { //위에걸 선택할 수 있는 상태이면(UP or BOTH)
ans = max(ans, arr[len][UP] + solve(len+1, DOWN)); //위에걸 선택
ans = max(ans, solve(len+1, BOTH)); //그냥 안선택
}
if (stat != UP) { //아래걸 선택할 수 있는 상태이면(DOWN or BOTH)
ans = max(ans, arr[len][DOWN] + solve(len+1, UP)); //위에걸 선택
ans = max(ans, solve(len+1, BOTH)); //그냥 안선택
}
return dp[len][stat] = ans;
}
int main() {
int t;
cin >> t;
while(t--) {
cin >> n;
for (int i=0; i < n; i++) {
cin >> arr[i][UP];
}
for (int i=0; i < n; i++) {
cin >> arr[i][DOWN];
}
memset(dp, -1, sizeof(dp));
cout << solve(0, BOTH) << '\n';
}
return 0;
}
N이 주어졌을 때, 특정 수 x보다 작거나 같은 수의 개수를 O(N)만에 계산할 수 있는데, 이를 이용하여
x보다 작거나 같은 수의 개수가 K와 비슷해질때까지 바이너리 서치를 합니다.
x보다 작거나 같은 수의 개수를 num(x) 라 할 때
바이너리 서치와 약간 다른 점은, K와 완전히 같은 num(x)가 존재하지 않을 수 있습니다.
따라서 K보다 큰 num(x) 중 최소 값을 갖는 x를 구해야 하며, num(x) == num(x+1) == ... == num(x+a) 와 같이 같은 값들을 가지는 num(x)들이 있을 수 있습니다. 이들 중에서는 가장 작은 x값이 정답이 됩니다.
num(x) == num(x+1) == ... == num(x+a)와 같은 관계에서는 x는 실제 N*N 매트릭스에 존재하는 값이지만, x+1은 존재하지 않는 값이기 때문입니다.
코드는 아래와 같습니다.
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
ll num(ll v, ll N) {
ll ret = 0;
//v보다 작거나 같은 원소 개수를 리턴함
for (int i = 1; i <= N; i++) {
ret += min(N, v / i);
}
return ret;
}
ll solve(ll N, ll K) {
//binary search 할 예정인데
// K보다 크거나 같은 값 중 최소 값 구할 예정. (중복 수 있을 수 있으므로)
// K와 같은 값이면 그중에 가장 작은 값
ll l = 1, r = N*N;
while (l < r) {
ll m = (l + r) / 2;
long long n = num(m, N);
if (n == K) {
ll v = m - 1;
while (n == num(v, N)) {
v--;
}
r = v + 1;
break;
}
else if (n > K) {
r = m;
}
else if (n < K) {
l = m + 1;
}
}
return r;
}
int main() {
ll N, K; cin >> N >> K;
cout << solve(N, K) << endl;
return 0;
}
퀄리피케이션 라운드는 절대평가(30점)에다가 27시간동안이나 대회를 하므로 간단하게 풀어버리고
약속에 가려고 했으나, 현실은 약속시간 내내 3번째 문제 솔루션을 생각했다.
가볍게 첫번째 문제 Foregone Solution 문제를 보았다. 히든케이스 10^100를 커버하기 위해 익숙하지 않은
파이썬으로 해결했다.
모든 4를 3으로 바꾸어 버리는 식으로 코드를 짰다.
tc=int(input())
def solve(n):
a=int(str(n).replace('4', '3'))
b=n-a
return str(a) + " " + str(b)
for t in range(1, tc+1):
n=int(input())
ans=solve(n)
print ("Case #" + str(t) + ": " + ans)
두번째 문제 You can go your own way
대충 문제 읽어보니까 솔루션이 떠올랐는데, 너무 간단해서 함정이 있나 조금 생각했다. E와 S를 서로 바꾸어주면 간단히 해결된다.
요녀석은 빅인티저같은게 필요가 없어서 주력언어인 C++로 작성했다.
#include <bits/stdc++.h>
using namespace std;
int main() {
int tc;
scanf("%d", &tc);
for (int t=1; t<=tc; t++) {
int n; scanf("%d", &n);
string s;
cin >> s;
printf("Case #%d: ", t);
for (size_t i=0; i < s.length(); i++) {
if (s[i] == 'S') putchar('E');
else putchar('S');
}
putchar('\n');
}
return 0;
}
세번째 문제, 욕심부리다가 엄청 오랫동안 생각했다.
간단하게 gcd를 구해서 하면 될 거라 생각했는데, 같은 숫자가 나오는 것을 간과했어서 WA를 엄청나게 뿜었다.
파이썬으로 제출한 것은 RE도 자주나왔다. 이유는 아직도 모르겠다..
원문이 AAA ABA 형식으로 나오게 되면, 인접한 cipher int value 가 동일한 값이 나오기 때문에 그냥 gcd를 구하면 1이 나오게 된다.
이 점을 유의해야 한다는 것을 까먹었다.
Runtime Error 때문에 C++로 솔루션을 작성해 보고, 후에 Python 으로 바꾸어서 히든케이스를 대비했다.
사용된 소수들은 인접 값이 다를때만 gcd로 죄다 구하면 되고, 해독할때는 소수 하나만 찾아내서 양옆으로 propagation 시키면 됬던 풀이이다.
일단 씨쁠쁠 풀이이다.
#include <bits/stdc++.h>
using namespace std;
int N, L;
int plainValue[105];
int main() {
int tc; cin >> tc;
for (int t=1; t<=tc; t++) {
memset(plainValue, 0, sizeof(plainValue));
cin >> N >> L;
vector<int> ciphers;
set<int> primes;
map<int, char> int2char;
map<char, int> char2int;
ciphers.clear();
primes.clear();
int2char.clear();
char2int.clear();
for (int i=0; i < L; i++) {
int tmp; cin >> tmp;
ciphers.push_back(tmp);
}
for (int i=0; i< L-1; i++) {
if (ciphers[i] != ciphers[i+1]) {
int cd = __gcd(ciphers[i], ciphers[i+1]);
primes.insert(cd);
primes.insert(ciphers[i]/cd);
primes.insert(ciphers[i+1]/cd);
}
}
char c = 'A';
for (auto& p : primes) {
if (int2char.find(p) == int2char.end()) {
char2int[c] = p;
int2char[p] = c++;
}
}
int idx, pval, ppval;
for (idx=0; idx < L-1; idx++) {
if (ciphers[idx] != ciphers[idx+1]) {
int cd = __gcd(ciphers[idx], ciphers[idx+1]);
plainValue[idx+1] = cd;
pval = ciphers[idx+1] / cd;
ppval = ciphers[idx] / cd;
break;
}
}
for (int i=idx; i >= 1; i--) {
plainValue[i] = ppval;
ppval = ciphers[i-1] / ppval;
}
plainValue[0] = ppval;
for (int i=idx+2; i < L; i++) {
plainValue[i] = pval;
pval = ciphers[i] / pval;
}
plainValue[L] = pval;
printf("Case #%d: ", t);
for (int i=0; i <= L; i++) {
putchar(int2char[plainValue[i]]);
}
putchar('\n');
}
}
이렇게 짠 녀석을 그대로 파이썬으로 옮기면 히든케이스도 커버할 수 있다.
def gcd(x,y):
while(y):
x,y=y,x%y
return x
def make_unique(l):
t = []
for v in l:
if len(t)==0 or t[-1] != v:
t.append(v)
return t
tc=int(input())
for t in range(1, tc+1):
plainValue = [0 for i in range(0, 110)]
N, L = map(int, input().split(' '))
ciphers = list(map(int, input().split(' ')))
primes = []
int2char = {}
for i in range(0, L-1):
if ciphers[i] != ciphers[i+1]:
cd = gcd(ciphers[i], ciphers[i+1])
primes.append(cd)
primes.append(ciphers[i]//cd)
primes.append(ciphers[i+1]//cd)
primes.sort()
primes = make_unique(primes)
c = 'A'
for p in primes:
if int2char.get(p) == None:
int2char[p] = c
c = chr(ord(c) + 1)
idx = 0
pval = 0
ppval = 0
for idx in range(0, L-1):
if ciphers[idx] != ciphers[idx+1]:
cd = gcd(ciphers[idx], ciphers[idx+1])
plainValue[idx+1] = cd
pval = ciphers[idx+1] // cd
ppval = ciphers[idx] // cd
break
for i in range(idx, 0, -1):
plainValue[i] = ppval
ppval = ciphers[i-1] // ppval
plainValue[0] = ppval
for i in range(idx+2, L):
plainValue[i] = pval
pval = ciphers[i] // pval
plainValue[L] = pval
ans = ""
for i in range(0, L+1):
ans += int2char[plainValue[i]]
print ("Case #" + str(t) + ": " + ans)
마지막 문제의 경우는 아직 풀지를 못했는데, 나중에 여유가 되면 한번 풀어보고 올려보도록 하겠다.
N, M, D값이 크지 않으므로, 하나하나 다 따라가는 시뮬레이션 방식으로 풀이하면 됩니다.
test(a,b,c) 함수는 궁수의 위치가 각각 (N, a) (N, b) (N, c)일때 최대로 잡을 수 있는 적의 수를 리턴합니다.
choose_turn 함수는 각각의 턴마다 각각의 궁수가 공격할 적의 위치를 set에 추가합니다.
#include <bits/stdc++.h>
using namespace std;
int N, M, D;
int field[16][16];
typedef struct _Pos {
int x, y;
bool operator<(const struct _Pos& rhs) const {
return x != rhs.x ? x < rhs.x : y < rhs.y;
}
} Pos;
inline int dist(int x1, int y1, int x2, int y2) {
return abs(x1-x2) + abs(y1-y2);
}
inline int dist(Pos p1, Pos p2) {
return abs(p1.x - p2.x) + abs(p1.y - p2.y);
}
void choose_target(int mmap[][16], set<Pos>& kset, int turn, int archer_pos) {
Pos archer = { N, archer_pos };
Pos vic_pos = { 1000, 1000 };
int pd = dist(archer, vic_pos); //previous dist
for (int i=0; i< N - turn; i++) {
for (int j=0; j < M; j++) {
if (mmap[i][j] == 0) continue;
Pos epos = { i + turn, j };
int d = dist(archer, epos);
if (d <= D) {
if (d < pd || (d == pd && epos.y < vic_pos.y)) {
pd = d;
vic_pos = epos;
}
}
}
}
if (vic_pos.x != 1000) kset.insert({ vic_pos.x - turn, vic_pos.y });
}
int test(int a, int b, int c) {
//archer pos = (N, a) (N, b) (N, c)
int kill = 0; //ret val
int mmap[16][16];
for (int i=0; i < N; i++)
for (int j=0; j < M; j++)
mmap[i][j] = field[i][j];
set<Pos> kill_set;
kill_set.clear();
for (int t=0; t < N; t++) {
//for each turn
choose_target(mmap, kill_set, t, a);
choose_target(mmap, kill_set, t, b);
choose_target(mmap, kill_set, t, c);
kill += (int)kill_set.size();
for (auto& v : kill_set) {
mmap[v.x][v.y] = 0;
}
kill_set.clear();
}
return kill;
}
int main() {
cin >> N >> M >> D;
for (int i=0; i < N; i++)
for (int j=0; j < M; j++)
cin >> field[i][j];
int ans = 0;
for (int i=0; i < M-2; i++)
for (int j=i+1; j < M-1; j++)
for (int k=j+1; k < M; k++)
ans = max(ans, test(i,j,k));
cout << ans << endl;
return 0;
}