----------------------------------------------------------------------------------------
- 이 글은 2020-01-08에 마지막으로 수정되었습니다.
- 글 상에 오류나 틀린 내용이 있을 수 있습니다.
- 잘못된 내용에 대한 신고나, 피드백을 주시고자 한다면 댓글을 달아주시면 반영하도록 하겠습니다.
----------------------------------------------------------------------------------------
개발을 시작하면서 접하기 쉬운 단어 중 햇갈리기 쉬운 API, ABI, 라이브러리, 프레임워크의 뜻을 알기쉽게 한번 설명해보는 포스팅이다.
계속 개발을 진행하다 보면 이런 용어들에 대한 대략적인 의미는 감이 잡히지만 정확한 뜻을 알거나 남에게 개념을 설명하기에는 햇갈릴 수 있다. 이번 포스팅을 계기로 한번 정리해보자.
라이브러리
일단 첫번째로 라이브러리이다.
컴퓨팅에서 라이브러리(Library)의 위키백과에서의 정의는 다음과 같다.
https://ko.wikipedia.org/wiki/라이브러리_(컴퓨팅)
소프트웨어를 개발할 때, 컴퓨터 프로그램이 사용하는 비휘발성 자원의 모임이다. 구성 데이터, 문서, 도움말 자료, 메시지 틀, 미리 작성된 코드, 서브루틴(함수), 클래스, 값, 자료형 사양 등을 포함할 수 있다.
예를 들어서, 누군가가 이전 C++포스팅에서 언급한 big_integer 클래스를 만들었다고 가정해보자. 아주 잘 만들어서 버그도 거의 없고, 정의된 함수만 잘 호출하면 잘 동작한다고 하자. 이 big_integer 클래스를 만든 사람이, 이 클래스를 혼자서 쓰기 아까워서 남들도 쉽게 사용할 수 있도록 공개를 해서 남들도 사용할 수 있도록 하되, 소스코드는 공개를 하고 싶지 않다면 어떻게 할까?
일반적으로 다음과 같은 절차를 밟는다. 클래스의 멤버변수와 멤버 함수들을 선언한 헤더파일과, 함수 정의부분을 컴파일한 목적 파일(Object File)을 만들고 사용 방법에 대한, 즉 클래스의 생성자 인자라던지 함수 사용 별 동작되는 방식이라던지 이런 부분에 대한 설명이 들어간 문서를 같이 공유하면 된다.
그러면 이 big_integer 클래스 사용하고 싶은 다른 개발자는, big_integer의 소스코드는 볼 수 없지만, 제공받은 헤더파일과 컴파일된 목적 파일, 그리고 사용법을 확인해서 자신의 프로젝트에서 그 개발자가 작성한 big_integer 클래스를 자유로이 쓸 수 있게 된다. 이 때, big_integer 클래스의 헤더파일과 컴파일된 목적 파일, 그리고 사용 방법에 대한 문서는 "C++ big_integer 라이브러리"가 된다.
그리고 여기서 big_integer 클래스의 생성자의 인자와, add 함수의 인자 및 리턴 타입 등 big_integer 클래스를 사용하기 위한 메소드 프로토타입들은 이 C++ big_integer 라이브러리의 "API"가 된다.
API
API의 정의에 대해 다시 자세히 설명해보겠다.
API는 일단 Application Programming Interface의 약자이다. 여기서 Application이란 Application Program이란 뜻으로, 한글로는 응용 프로그램이다.
컴퓨터 프로그램은 크게 응용 프로그램과 시스템 프로그램으로 나뉘는데, 시스템 프로그램이 아니면 모두 응용 프로그램이라고 보면 된다. 시스템 프로그램은 쉽게 말하면 운영체제이다. 따라서 간단하게 생각하면 'Application -> 운영체제가 아닌 모든 프로그램' 이다.
Programming은 프로그램을 만드는 것을 뜻한다. 따라서 API는 응용 프로그램을 만들 때 사용하는 인터페이스라는 뜻이 되는데, 그러면 인터페이스는 무엇을 뜻하는가?
예를 한번 들어보겠다. 노트북에 USB 메모리를 연결해서 데이터를 전송하려고 한다. 이 때, 노트북과 USB 메모리의 인터페이스는 무엇일까?
USB포트가 이 서로 다른 두 물체의 인터페이스다. 인터페이스는 간단하게 서로 다른 두 개 이상의 것들을 이어주는 '매개체'라고 생각하면 된다.
API는 따라서 응용 프로그램을 작성할 때 필요한 매개체라는 해석이 가능하다. 그러면 매개체가 왜 필요한 것일까?
실무 개발에서는 프로그램의 크기가 커지면 혼자서 밑단 부터 윗단 까지 모두 다 개발할 수 없다. 따라서 서로간의 협업이나 이미 만들어진 소프트웨어 컴포넌트를 결합해서 만드는데, 이 때 라이브러리도 그 중 하나이다. 그러한 컴포넌트들을 결합하기 위한 매개체들을 API라고 하는 것이다.
C++ 어플리케이션을 작성할 때 다른 C++ 클래스 라이브러리를 사용하는 경우 해당 클래스에 정의된 메소드들을 실행함으로써 해당 라이브러리를 활용한다. 따라서 해당 메소드들의 필요한 인자나 리턴 타입 등이 C++ 클래스 라이브러리의 API가 되는 것이다.
그런데 보통 외부 컴포넌트의 경우 라이브러리 형태로 제공받는 경우가 많아서 라이브러리와 API의 뜻을 햇갈려하는 경우가 많다. 하지만 라이브러리는 이러한 컴포넌트 자체를 뜻하고, API는 이 컴포넌트를 활용하는 규약이라고 보면 된다. 다음 예에서 라이브러리가 아니지만 API를 제공하는 경우를 확인해보자.
구글 클라우드에서 제공하는 Speech API가 있다.(이름 부터 대놓고 API이다)
음성 데이터를 넣으면 그 데이터를 원하는 언어의 텍스트로 인식해서 돌려주는 방식이다. 그리고 기계학습을 이용한 인공지능 기술로 해당 기능을 구현하였다고 하고, 내부적인 동작은 공개하지 않고 있다. 그리고 여기서 제공하는 RESTful API의 경우는 특정한 포맷에 맞추어서 HTTP 음성 데이터를 포함한 요청을 보내면 HTTP 응답으로 해석해낸 텍스트가 돌아오는 방식이다. 이 때 HTTP 요청/응답 포맷 역시 API이며, 이는 개발자의 로컬 컴퓨터에 설치된 라이브러리를 통해 제공받는 방식이 아니다. 외부 원격에 있는 서버에서 부터 이러한 음성 인식 서비스를 제공받는 것이다.
이 경우는 라이브러리가 아니지만 API를 제공한다.
ABI
이제 API와 차이점을 잘 알기 어려워 할 수 있는 ABI에 대해 알아보자.
API라는 단어는 흔히 접하게 되어서 대략적으로도 뜻을 알기 쉬운데 ABI는 자주 접하는 단어는 아니다. ABI는 Application Binary Interface의 약어로 직역해보면 응용프로그램 이진 인터페이스이다. 응용프로그램과 다른 컴포넌트간에 이진 인터페이스인데, 이때 이진은 Binary로 0과 1을 뜻하는데 컴퓨터에서 가장 로우레벨, 가장 기계와 가까운 수준으로 내려가게 되면 0과 1로 이루어진 이진값들로 가게 된다. 기계 수준, 이진값 수준에서 인터페이스를 뜻한다. API는 소스코드 레벨에서 호환이 된다면, ABI는 바이너리 수준에서 호환이 된다고 한다.
바이너리 수준에서 호환이 된다고 하면 바이너리로 이루어진 기계어들과 관련이 있다고도 볼 수 있겠다.
이 기계어들은 결국 물리적인 프로세서, 즉 CPU에서 실행을 하고, CPU들이 실행하는 기계어 명령어 셋들을 ISA(Instruction Set Architecture)라고도 부른다. 이 ABI는 실질적으로 ISA와 밀접한 관련이 있다고 볼 수 있다.
아까 라이브러리와 API를 햇갈려 하듯이, ABI와 ISA는 햇갈릴 수 있는 관계라고 볼 수 있다.
하지만 의미상으로는 ISA는 해당 하드웨어 프로세서가 실행할 수 있는 기계어 명령어 세트를 의미하고, ABI는 바이너리 코드 레벨에서 호환되는 인터페이스를 의미한다.
아래는 안드로이드 스튜디오에서 에뮬레이터를 생성하려고 할 때 고르는 화면이다. 우측에 보면 CPU/ABI라고 되어 있는 항목이 있다. x86이라고 쓰여 있는데 이는 흔히 쓰이는 Intel에서 개발한 유명한 32bit CPU 아키텍쳐 중 하나이다. CPU라고도 같이 쓰여있는 것으로 보아 ABI와 CPU 아키텍쳐는 여기서는 사실상 같은 의미로 쓰이고 있다고 볼 수 있다.
API라고 쓰여있는 부분도 있는데, 여기서 API는 안드로이드 API 버전을 의미하며, API level 28는 안드로이드 PIE 버전을 의미한다. API Level 27 안드로이드 환경에서 앱을 만들때와, API Level 28에서 안드로이드 환경에서 앱을 만들 때, 소스코드의 형태가 다를 수 있다는 것을 시사하는 것이다.
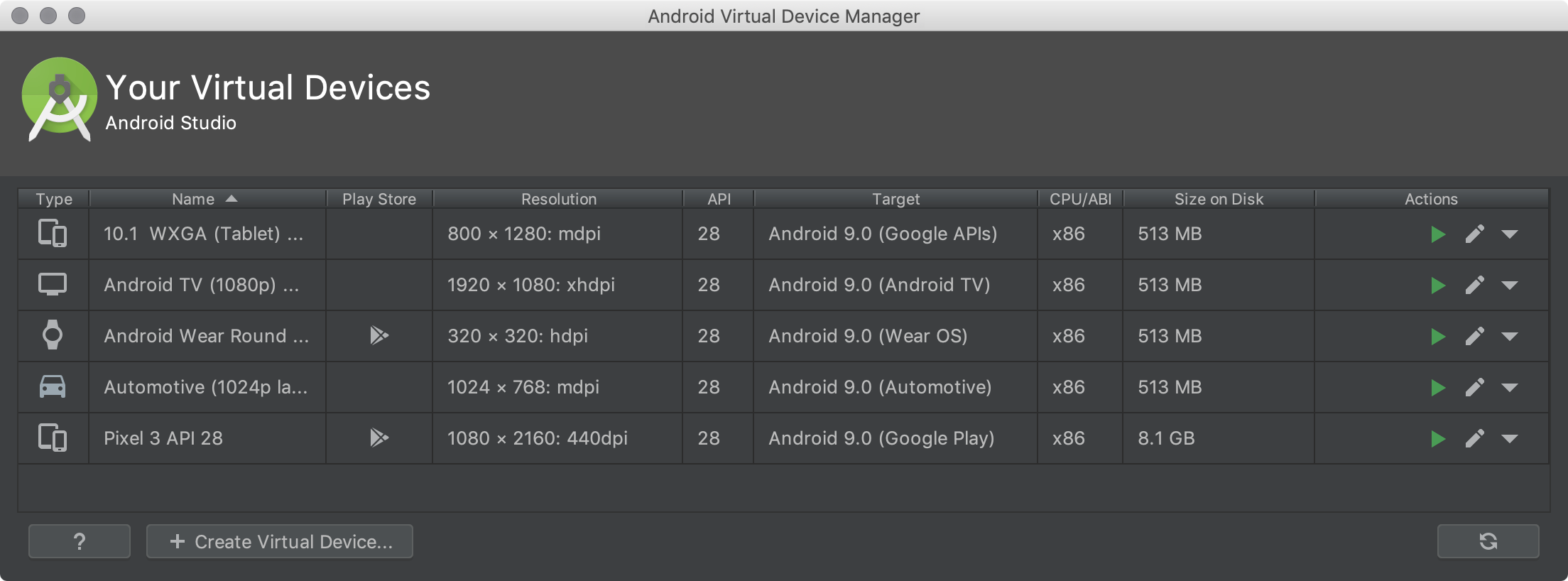
이렇게 이야기를 하면 이해가 어려우므로 예를 들어서 설명해보도록 하겠다.
Windows 운영체제에서 다음과 같은 Hello World 코드를 작성해서 컴파일 후 실행해 보았다.
#include <stdio.h>
int main() {
printf("Hello World!\n");
return 0;
}
이 코드를 그대로 복사해서 Ubuntu Linux 환경에서 컴파일 후 실행하면 같은 결과가 나올까?
정답은 당연히 Yes이다. 왜냐하면 윈도우 환경과 리눅스 환경에서 표준 입출력 라이브러리에 구현된 printf 함수의 스펙이 같기 때문이다. 받는 인자와 결과가 같기 때문이다.
이것은 윈도우와 리눅스의 printf 함수의 API가 호환이 되기 때문이라고 볼 수 있다. 호환이 된다는 것은 같은 입력값을 넣었을 때 같은 결과값이 나타난 다는 것이다.
그러면 만약 x86 CPU를 사용하는 윈도우 시스템에서 대충 다음과 같은 어셈블리 코드를 실행한다고 생각해보자.
[BITS 32]
mov ax, 0x01
ax레지스터에 1이라는 값을 넣는 결과가 나타날 것이다.
그러면 이 똑같은 코드를 기반으로 x86 CPU를 사용하는 리눅스 시스템에서 같은 코드를 실행한다면 같은 결과가 나올까?
이 질문의 답도 Yes이다. 어셈블리 언어는 바이너리 값과 1대 1 매칭이 되므로, 어셈블리 수준에서 호환이 된다는 것은 바이너리 수준에서 호환이 된다고 볼 수 있다. 같은 바이너리 값을 실행했을 때 같은 결과가 나타난다면 바이너리 수준에서 호환이 된다고 볼 수 있다.
이 경우 ABI가 호환된다고 볼 수 있다.
두 시스템 다 x86 계열 CPU를 사용을 하기 때문에 나타나는 것으로, 같은 기계어 Instruction에 대하여 똑같이 동작하기 때문에 ABI가 호환이 되는 것이다.
"""
여기서 살짝 궁금증이 있을 수 있는 부분은 ABI가 호환된다면, 윈도우에서 컴파일한 Hello World 실행파일이 리눅스에서는 왜 똑같은 결과를 내면서 실행이 되지 않느냐라는 것인데, 이는 윈도우와 리눅스의 운영체제별 실행파일의 포멧이 다르기 때문이다. 그리고 공유 라이브러리의 존재 유무와 공유 라이브러리의 포맷 등 다른 여러가지 요인들이 섞여있기 때문이다. 따라서 ABI에 대한 예제로 해당 Hello World 실행파일을 주지 않았다.
"""
이러한 개념이다. 따라서 API는 소스코드 레벨의 호환성을 보장하고, ABI는 바이너리 레벨의 호환성을 보장하는 의미이다.
그러면 다음의 사례는 어떠할까?
A 라는 라이브러리를 사용하는 소프트웨어가 있다. A라이브러리의 버전이 업그레이드 되어서 API가 바뀌었다. 이 때 해당 소프트웨어는 A라이브러리와의 호환성을 유지하기위해 어떠한 조치를 취해야 하는가?
=> API가 바뀌었으므로 소스코드를 수정해야 한다.
B라는 소프트웨어는 x86 시스템에서 사용하도록 컴파일되었다. 하지만 이 소프트웨어를 ARM 시스템에서도 사용할 수 있는 버전을 만들려면 어떻게 해야하는가?
=> ABI가 다른 시스템으로 이식해야 한다. 소스코드->바이너리로의 변환은 컴파일러가 해줄 수 있으므로, ARM용 컴파일러나 크로스 컴파일러를 이용해서 새로 컴파일하면 된다.
프레임워크
이제는 프레임워크에 대하여 이야기 해 보겠다. 보통 프레임워크와 라이브러리를 햇갈려 하는 사람들이 많다.
사실 프레임워크라는 단어는 소프트웨어 분야 외에서도 쓰이는 단어이다. 직역하면 뼈대, 골조라는 뜻이고, 만약 경영학과를 전공 한 사람이라면, 프레임워크라는 단어를 한번 쯤은 들어봤을 것이다.
이러한 SW가 아닌 분야에서 프레임워크라고 하면 "문제를 바라보는 틀", 혹은 "대상을 바라보는 시각과 관점" 등 의 다양한 의미를 지니고 있다.
위키에서의 정의는 다음과 같다.
소프트웨어 프레임워크(software framework)는 복잡한 문제를 해결하거나 서술하는 데 사용되는 기본 개념 구조이다. 간단히 뼈대, 골조(骨組), 프레임워크(framework)라고도 한다. 이렇게 매우 폭넓은 정의는 이 용어를 버즈워드(buzzword)로서, 특히 소프트웨어 환경에서 사용할 수 있게 만들어 준다.
SW분야에서 프레임워크와 일반적인 프레임워크에서 공통되는 부분은 "틀"이라는 부분이다.
무언가를 하기 위한 '틀'에 해당된다.
흔히 이야기하는 "틀에 박힌 사고방식"라는 관용어구에 있는 그 "틀"과 같다고 볼 수 있다.
이 틀이 있음으로써 가지는 장점은 무언가를 해결해야 하거나 할 것이 있을 때, 그 틀에 맞추어서 행동을 하면 누구나 쉽게 따라하면서 해결 해 나갈 수 있다.
반면 단점으로는 그 틀에 맞지 않는 무언가는 해결할 수 없다는 점이 있다.
소프트웨어 프레임워크도 마찬가지이다. SW 프레임워크는 어떠한 문제를 해결하기 위한 소프트웨어적 틀에 해당한다.
예시로 매우 유명한 프레임워크 중 하나인 안드로이드 프레임워크를 들어보겠다.
(사실 안드로이드 시스템은 안드로이드 커널 위에 안드로이드 프레임워크가 올라가는 형식으로 이루어져 있다.)
안드로이드 프레임워크는 안드로이드 시스템에서 구동가능한 안드로이드 앱을 만들 수 있는 API들을 제공을 한다.
OnClickListener라는 java나 코틀린 메소드를 오버라이딩 하면 어떤 View를 눌렀을 때 어떤 동작을 할 것인지를 지정할 수 있고, 실제로 그 뷰를 클릭했을 때 해당 동작이 일어나게 해준다.
이러한 기타 등등의 작업들만 하고 앱을 빌드하면 원하는 대로 동작하는 안드로이드 앱이 생성이 된다.
API대로만 구현을 하면 앱 내부적으로는 어떠한 최적화나 연산을 하는지는 알 수 없지만, 원하는 대로 동작한다는 것 만 알 수 있다.
이 안드로이드 프레임워크는, 안드로이드 앱을 만들기 위한 정해진 틀이라고 볼 수 있는 것이다.
하지만 안드로이드 프레임워크로는 웹 서버를 만들 수 없다. 왜냐하면, 안드로이드 프레임워크는 안드로이드 앱을 만들기 위한 "틀"이므로, 틀의 원래 목적과 다른 웹 서버를 만들 수는 없다.
그렇다면 라이브러리와 프레임워크는 어떻게 다른 것일까?
일반적으로 프레임워크 안에 라이브러리가 포함되는 경우가 많다. SW 프레임워크는 보통 어떤 거대한 응용프로그램 등을 만들기 위한 "틀"인 경우가 많은데, 이를 위해서 미리 코딩된 코드조각들은 거의 당연히 들어가있다고 볼 수 있다.
이 "미리 코딩된 코드조각"들은 라이브러리에 해당된다고 볼 수 있다.
다만 라이브러리만 가져다 쓰는 경우는, 프로그램의 메인은 개발자가 직접 쓰고, 중간중간 필요한 부분만 라이브러리로 가져와서 쓰는 형태인 반면, 프레임워크를 가져다 쓰는 경우, 그 프레임워크의 본디 목적과 다른 프로그램은 만들 수가 없다.
프레임워크가 라이브러리에 비해 해 주는 일이 더 많고, 규모가 거대한 만큼 원래 목적과 다른 일은 할 수 없다는 점이 다르다고 볼 수 있다.
아래 KLDP에서 프레임워크와 라이브러리 차이에 대한 쓰레드가 열린 적이 있는데, main문을 바꿀 수 있으면 라이브러리고 아니면 프레임워크다 하는 식의 이야기도 나오곤 한다.
https://kldp.org/node/124237
사실 프레임워크의 정의 자체가 매우 엄밀한 정의는 아니므로 몹시 까다롭게 따질 필요는 없으나, 소프트웨어 분야에 종사하는 사람으로써 매우 자주 쓰이는 용어 중 하나이므로, 한번 짚고 넘어갈 필요는 있다고 생각한다.




